Faster Than Joins! Power Query Record as Dictionary: Part 3
This is the third post in the “Power Query Think Tank” series. This post is based on the several posts, initially written by Mikhail Muzykin for the Telegram channel “For those from the tank”, and they also was slightly rewritten and enriched for better reading experience, plus I added some of my thoughts and explanations.
Record.From… – different ways to create dictionary from lookup table
In two previous posts in this serie (here and here) we mentioned that in Power Query “lookup record” approach could be really faster than standard nested join (or even the simple Table.Join) in some cases (especially when we are talking about the big lookup tables – more than 10,000 records).
Before we prove it, it is necessary to define the conditions and limitations of using lookup records instead of joins.
- First, we need to remember that the key in our dictionary is the text (name of the record field). If we need to make a lookup on number, date or other data types other than text, then we either need to convert these fields into text values (which adds a significant overhead costs to our query) or use joins on these fields.
- Second, the lookup record actually could replace the left outer join (most used in the Power Query), but it cannot replace the inner, full or left (or right) anti joins. The reason is that looking for the value in the lookup record allows us to create new columns in the table, but to alternate the number of rows we need to apply additional filtering, which could also add overhead costs to the query.
- Third, if we creating lookup record from some table using one or several columns of it to create field names/keys, we need to be sure that these keys are unique.
If we are ok with these limitations, then we can get 1.5-2 times faster (!) lookup, plus additional benefit: substitute not found elements with desired values in one step, when it is necessary.
There’re many ways to create records in Power Query. Which one is better (in performance terms) to use when we creating a lookup dictionary as an alternative to joins?
For this example, our goal is to get from this table:
|
1 2 3 4 5 6 7 |
LookupTable = #table( {"Position", "Salary", "Bonus"}, { {"Player", 1000, 100}, {"Coach", 2000, 5000} } ) |
the next record:
|
1 2 3 4 |
[ Player = {1000, 100}, Coach = {2000, 5000} ] |
This record we then will use to lookup values with the help of Record.FieldOrDefault.
To generate a record in M we can use at least three functions:
Record.AddField()
First function, Record.AddField, allows us to add only one field a time. It means that to populate dictionary record with all pairs “name-value” we need to call this function in a loop, for example, with the help of List.Accumulate.
First sample function adds fields to the initially empty record []:
|
1 2 3 4 5 6 |
List_Accumulate_v1 = (table)=> List.Accumulate( Table.ToRows(table), [], (s,c)=>Record.AddField(s,c{0},List.Skip(c)) ) |
And we can make it a little faster using Table.ToList with the list generator function, instead of skipping the first column value on each iteration:
|
1 2 3 4 5 6 7 8 |
List_Accumulate_v2 = (table)=>List.Accumulate( Table.ToList( table, (row)=>{ row{0}, List.Skip(row)} ), [], (state, current)=>Record.AddField(state, current{0},current{1}) ) |
Both functions above are quite performant when we are talking about dictionaries of the small size (up to 100 elements). When the size of the dictionary increased, these function became very slow and could even break the whole query. The reason is the List.Accumulate, but details of this behavior is out of scope of this post. So, when we are talking about relatively big dictionaries, avoid using these functions.
Record.FromTable()
The second approach is much faster: we can create the record from the table of two columns (“Name” and “Value”).
For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Record_FromTable_v1 =(table)=> let Names = Table.ColumnNames(table), CombineValues = Table.CombineColumns( table, List.Skip(nms), (x)=>x, "Value" ), Result = Record.FromTable( Table.RenameColumns( CombineValues, {nms{0},"Name"} ) ) in Result |
For small-sized dictionaries it is most performant, but then (when dictionary size increases) became more and more slowly (although not so slow as the first two variants).
Another use of Record.FromTable is very performant (we used it in the previous post):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Record_FromTable_v2=(table)=> Record.FromTable( Table.FromList( Table.ToList( table, (x)=>{ x{0}, List.Skip(x) } ), (x)=>x, {"Name", "Value"} ) ) |
It became noticeable slower than the best variants only on the relatively big dictionaries (more than 100,000 keys).
Record.FromList()
Last two variants are the most performant. They outperforms the regular joins for 15-20% when the size of the dictionary equal 10,000 keys and almost twice (!) when we the dictionary size is greater than 100,000 keys.
|
1 2 3 4 5 6 7 8 9 |
Record_FromList_v1 = (table) => Record.FromList( Table.ToList( table, (x)=>List.Skip(x) ), Table.Column( table, Table.ColumnNames(table){0}) ) |
Here we got the list of field names referring to the first column by its name, which looks a little bit wordy for that case.
But it could be easily fixed:
|
1 2 3 4 5 6 7 8 9 10 |
Record_FromList_v2 = (table) => Record.FromList( Table.ToList( table, (x)=>List.Skip(x) ), Table.ToColumns(table){0} ) |
Here we are taking the first column of the lookup table just by its position. After a lot of different tests this last variant presents itself as the most performant (slightly better than previous).
Faster than Joins
Here is the table with the test results. As you can see, on the small dictionaries there’s almost no difference what to use – Join, List.Accumulate or Record.FromTable/FromList. But when the dictionary size increases, we can easy recognize the leaders, and they are not built-in join functions. Surprise!
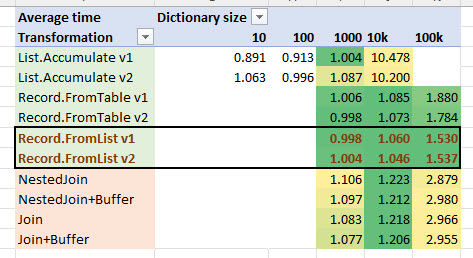
Target table has 100k rows, and each function was tested with the dictionaries of different size. Test were made in Excel with the help of Merka add-on. Each test was run 5 times, and all test were made on the same PC and under the same load.
Here is our testing query to compare performance of Table.Join/Table.NestedJoin with the Record.FieldOrDefault:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
let DictionaryRecord = fnDictGenerator(LookupTable), fnLookupGenerator = (RowValues as list) as list => RowValues & Record.FieldOrDefault(DictionaryRecord, RowValues{0}, {}), Result = Table.FromList( Table.ToList(TargetTable, fnLookupGenerator), (row)=>row, {"Name", "Occupation", "Salary", "Bonus"} ) in Result |
As you can see, DictionaryRecord is created by fnDictGenerator function, which takes LookupTable as its argument. This record then used by fnLookupGenerator which makes all heavy-lifting in adding new lookup columns to the TargetTable when used in Table.ToList function.
I don’t sure if we can find more performant way to lookup values in the record, but the performance of the whole query significantly depends on the record generator function.
So, if you are fighting with performance issues, here’s one of the pills. Just use it wise and only when needed 😉
Follow me:Share this: