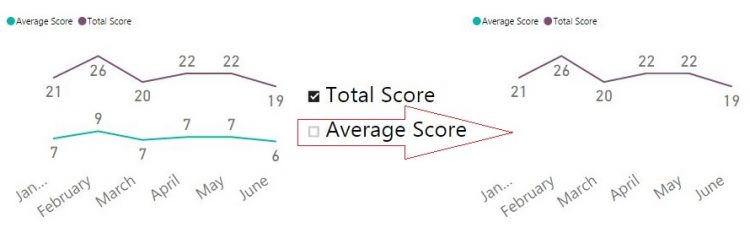
A few days ago a client asked me if it is possible to dynamically change series displayed on Power BI chart. My first (instinctive) answer was “Yes, of course, you can use a slicer to select which series you want to show, just put desired column in a slicer visual”. But then he added details: he wanted to select a measure to display on a chart, not to filter a value from column. My second (instinctive) answer was “No, you can’t. You can only filter a column, and can’t place measures in a slicer”.
But after a little chat I started to wonder whether it is really impossible. If we put a measure in a “Value” well of chart fields, it will be shown as a series (for example, some [Total Amount] measure). What my client is actually wants? He want to choose some elements on the slicer and, if one element selected, to show a measure. If that element is unchecked, then don’t show a measure.
Actually, those slicer’s elements are unique values from some column. A slicer applies a filter to that column. Can we catch whether a column is filtered? Yes, of course, we can do it with DAX. And if some desired value is selected, we just need to show a measure as a series. As that measure is already in the “Value” well of a chart, then, in other words, we just have to “do nothing”. So, we only need to somehow hide a measure if a desired slicer’s element didn’t selected.
Continue Reading →
Follow me: 


‘M’ (a Power Query Formula language) is a very powerful and interesting, but sometimes it could be a little confusing because of its lazy behavior.
Yesterday a friend of mine asked me for help with custom API connector in Power Query / Power BI. This connector has to work as follows:
- Post report requests
- Wait for reports completion
- Download reports
On the step 2 my friend used Function.InvokeAfter() built-in Power Query function, which supposed to pause code for a few seconds. But his code didn’t worked as expected – It looks like there are no requests posted at all.
We’ve found a solution to his task, but to make a long story short, there is what I have found from this case.
Let us look at this short code:
|
|
let a = DateTimeZone.LocalNow() - b, b = Function.InvokeAfter(DateTimeZone.LocalNow, #duration(0,0,0,2)) in a |
As we can imagine from ‘M’ evaluation rules, to get “a” we need to calculate “b” first. We can suppose that before evaluation of value “a” there goes value “b” evaluation. So, we’ll get “b” (current time), then extract current time from the same current time and get zero.
No way. The result is about -2 seconds: -00:00:02.0183210
Why? It is not so obvious, but there is a very easy answer: ‘M’ evaluates a value from left to right. When ‘M’ check for the a expression, it calculate first part:
Then it found “b” and evaluate it:
|
|
b = Function.InvokeAfter(DateTimeZone.LocalNow, #duration(0,0,0,2)) |
The result of “b” is the local datetime with 2 seconds delay, so it is two seconds later than “a”. Of course, a – b approximately equals to -2 seconds.
It is easy to check:
|
|
let a = b - DateTimeZone.LocalNow(), b = Function.InvokeAfter(DateTimeZone.LocalNow, #duration(0,0,0,2)) in a |
There I changed evaluation order in the “a” expression, so now “b” is evaluated first, then second part (
DateTimeZone.LocalNow() ) is evaluated. As this evaluation is very quick, we have no delay and got the same time as in “b”. The new result is 0, zero.
So, what I have found here is that relatively complex expressions in ‘M’ evaluates from left to right.
There is another interesting result. Let us see the next code:
|
|
let a = DateTimeZone.LocalNow(), b = Function.InvokeAfter(DateTimeZone.LocalNow, #duration(0,0,0,2)) in { Duration.Seconds(a-b), Duration.Seconds(b-a) } |
The result of this code should be a list with two values. What I expected from previous example? There should be something like {-2, 0}, like results of previous calculations.
No way. The result is {-2, 2}:
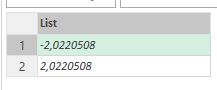
Why there is a different result?
The reason is the lazyness of ‘M’: when the first element of the list evaluated, then it works like in example above: evaluate “a” then evaluate “b” (plus 2 sec), extract “b” from “a”. But for the second element ‘M’ did not make any evaluations of “a” or “b”. They already evaluated, so, as “b” is bigger than “a” for 2 seconds, extraction gives me +2.
If I change the order of the list elements:
|
|
let a = DateTimeZone.LocalNow(), b = Function.InvokeAfter(DateTimeZone.LocalNow, #duration(0,0,0,2)) in {Duration.Seconds(b-a), Duration.Seconds(a-b)} |
The result will be {0, 0}:
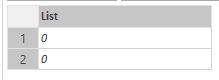
Now it is expected – values didn’t recalculated
Now I can easily explain why: when evaluating the first element, b-a, the “b” evaluated first, then “a” immediately evaluated and it equals to “b”, and we get a zero as the result of extraction. Already calculated “a” and “b” then swap their places and give us the same result.
It looks as a very interesting finding for me. I think I have to keep it in mind when I’ll try to implement some time-delayed evaluations in queries.
Follow me:
Maxim Zelensky
17 января, 2017
The history of “reinventing the bicycle” using DAX
Defining evaluation context and context transition rules is the most important and confusing part of DAX. Sometimes when you think you’ve already managed it, DAX turns to you with other side, hook, uppercut – and you’re knocked down.
Last week one of my Facebook friends asked me to explain why his measures working this way and not that way. It was quite easy questions and there is no sense to place them here. But my friend is a very curious man, one question led to another, and suddenly I found that I can’t explain a very simple, on the first look, concept. The question was about filtering under context transition in calculated column (here you can imagine a very big grin on DAX’s face).
For this post I reworked and simplified data model.
There are two tables, named
‘Managers’ and
‘Sales’ .
‘Managers’ has only two columns:
[Manager] and
[Department] .
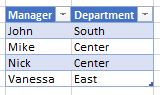
‘Managers’ table
‘Sales’ has a little bit more columns (although it doesn’t matter here):
[Order] ,
[Manager] ,
[Amount] and
[Order type] .
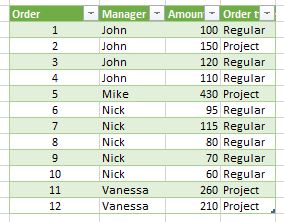
‘Sales’ table
As you can see, they are linked one-to-many by
[Manager] column. Quite easy.
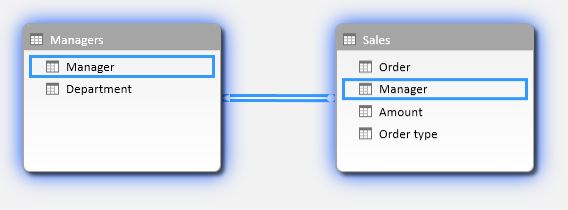
Data Model
First of all my friend asked me, how context transition works. “Hey, it’s easy!” – I said, and Continue Reading →
Follow me:
There are many ways to get a value from parameters table and then pass it to query. One of this methods uses direct selection of unique parameter name. I think it worth a post.
Items selection: brief reminder
As I described in my first ever post “Absolute and Relative References in Power Query”, when we would like to refer to a single item in a list or a cell in a Power Query table, we can use
Name{Argument} syntax:
TableName{Row} or
ListName{Element} . If
Name is a table or list, and
Argument is number, then it is simple: we asking for a row or element of such position.
The most commonly used syntax for single cell addressing in tables is
|
|
Table{RowNumber}[FieldName] |
But it is often omitted that if
Name is a table,
Argument could be not a number but a record:
Quick filter for unique values
Value passed as
Record in this expression works like a filter for a matching field in the table. For example,
[empl_name = “John”] .
How it works and what is in it for practical uses?
If
- our table has a column named
empl_name
and
- row with value “John” in this column could be found,
and
- this row is unique (i.e. there is only one row with value “John” in column
empl_name , matching to the
Record ),
then entire record (i.e. row) will be returned as the result of this expression. In other words, a unique matching record from the table.
But there is one important restriction: if there is no unique matching row in the table, an error is raised.
So, when
Table{Record} returns a desired result, it has type of record and we can reach a single item from this record by referring to desired field in it:
We can see this method in action when we build query to a table from Excel file. Power Query will create such string of code automatically:
|
|
= Excel.CurrentWorkbook(){[Name="Parameters"]}[Content] |
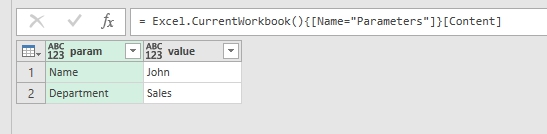
How Power Query refers to a table in Excel workbook
Implications
For example, we would like to implement table for passing user-defined parameters to Power Query (I recommend this great post “Building a Parameter Table” by Ken Puls):
|
|
myTable = #table(type table [param = text, value = text],{{"Name","John"},{"Department","Sales"}}), person = myTable{[param = "Name"]}[value], dept = myTable{[param = "Department"]}[value] |
In this example in the first row we create a parameters table with columns param and value that is supposed to be a parameters table for use in other queries.
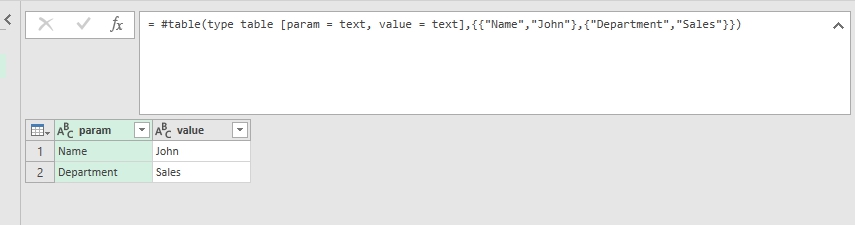
Hardcoded parameters table (just for sample)
Then we got a parameter’s value by applying “record filter” and selecting desired field (
[value]):
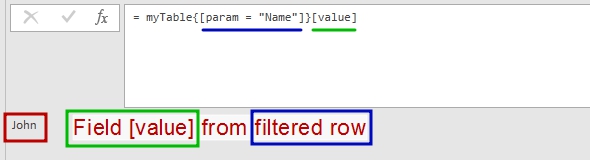
Now we can quickly get “Name” parameter’ value from the table above
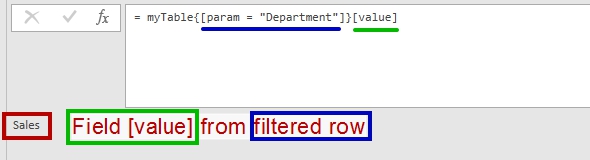
And “Department” parameter’ value from the table above. Any unique parameter.
What are the benefits in this approach?
- First of all, we do not need to remember a desired parameter row when coding (what if user swapped rows in parameters table?).
- Then, we do not need to filter parameters table each time to get a desired value.
- And also we can check for parameters table integrity – if there will be several rows with the same parameter name, or missing parameter value, or missing field, then we’ll got an error and can handle it.
And, don’t forget that this
Table{Record} method has a lot of other uses – when we really need to get a record as a result of expression. Also we can pass a more complex (with 2 or more fields) record as filter.
And
Argument record could be a result from other queries. Lets name this query as “QueryRecord”:
|
|
let Source = #table(type table [Name = text, Department = text, Region=text],{{"John","Sales","AL"},{"Jim","IT","FL"}}), QueriedRecord = Record.RemoveFields(Source{0},{"Region"}) in QueriedRecord |
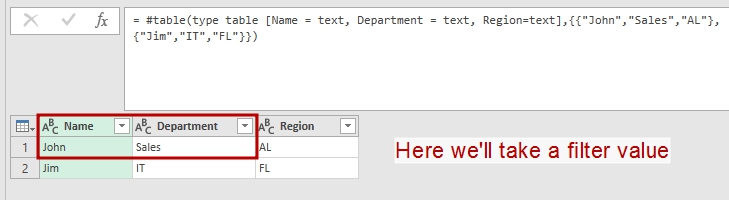
We’ll take a record from this table
The result of above query is a record with two fields:
[Name = "John", Department = "Sales"] .
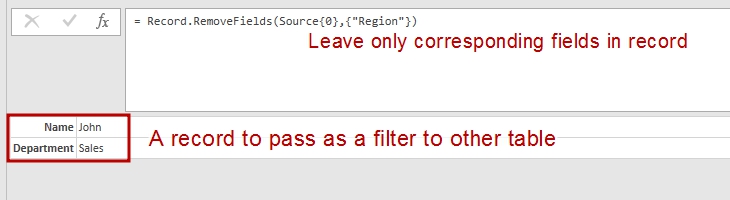
I leaved only needed fileds in this record
Then we pass it as an filter argument to other table:
|
|
let Source = #table(type table [Name = text, Department = text, Date = text],{{"John","Sales","01.01.16"},{"Jim","IT","02.01.16"}}), ChType = Table.TransformColumnTypes(Source,{{"Date", type date}}), Filtered = try ChType{QueryRecord} otherwise null in Filtered |
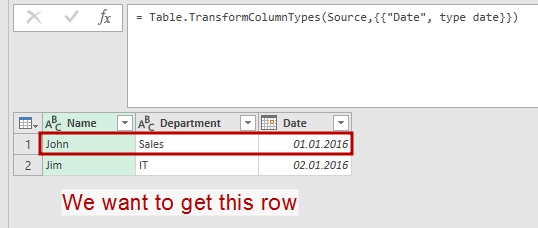
We will filter this table with the result of previous query
The result is a desired record:
|
|
[Name = "John", Department = "Sales", Date = "01.01.2016"] |
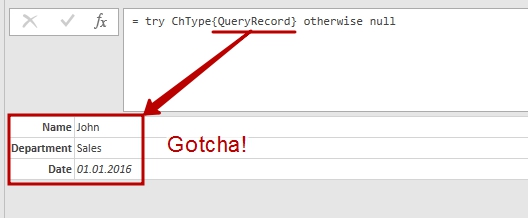
Hey-ho, it works!!!
Another one “Get parameter” function
And a cherry on the cake – quick parameter selection function. You can easy change it for your needs:
|
|
(param_table as table, param_name as text) => let fnParam = try param_table{[param=param_name]}[value] otherwise null in fnParam |
You can also find a complete description of item selection in “Microsoft Power Query for Excel Formula Language Specification” (see “6.4.1 Item Access” on page 59 in August 2015 edition).
Follow me:
PowerQuery is a great instrument that can do much more than just take data from source and pull it in a table or Power Pivot. We can clear and transform data in multiple ways, but there are some transformations, usual in Excel, which are not so convenient to make in Power Query.
For example, what if I need a relative reference to a specific “cell” (a value from exact row in exact column) in a PowerQuery table? Or reference to a value that is in specified column and 4 rows above from referencing row? In Excel this is obvious, I need just point on it with mouse, ensure that I removed “$” (absolute) signs from row part of reference, that’s all. But in PowerQuery I can’t do this so easy.
But anyway, a solution, still obscure, is reachable.
First of all, let’s found how we can access a particular value from a Power Query table.
The easiest way to understand item addressing in Power Query, in my mind, is analyzing of steps code.
Absolute row references
Suppose we have a simple table of two columns, “Date” and “Amount”. It has 5 rows, and in the first column it filled with, suddenly, dates, in second – some values:
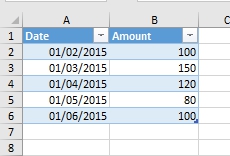
Source table
We would like to get a value from cell B4, exactly 120. Continue Reading →
Follow me: