Faster Than Joins! Power Query Record as Dictionary: Part 3
Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →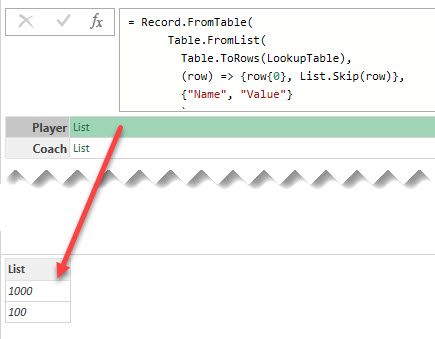
Using the Record.FieldOrDefault function in Power Query to lookup values from dictionary record and handle missing keys
Continue Reading →На днях я провел несколько увлекательных часов, пытаясь найти причину, по которой Power BI отказывался строить связь «один-ко-многим» между двумя таблицами – справочником и таблицей фактов. Эта короткая история в очередной раз говорит нам: «Век живи – век учись»
Ошибка, на которую указывал Power BI, звучит приблизительно так: «невозможно установить связь – как минимум один из столбцов, участвующих в связи, должен содержать уникальные данные»
Связь между двумя столбцами должна была строиться по текстовому полю [SKU Name], содержащему названия SKU (я понимаю, что это не лучший вариант, но таковы условия проекта), источник данных – таблицы Excel.
Так как в таблице фактов значения не предполагали уникальности, было понятно, что нужно искать проблему именно в справочнике, где они должны быть уникальными.
Обнаружить дубликаты в редакторе запросов Power Query не получалось ну совсем никак:
[SKU Name] не изменило количество строк.Text.Clean) значений столбца. Это тоже не помогло удалить дубликаты, но зато увеличилось количество звучащих в моем домашнем офисе непечатных выражений.Table.Distinct(Table, {{“SKU Name”, Comparer.FromCulture(“en-us”, true)}}). Не помогло…Обнаружить дубликаты в источнике (файлах Excel) тоже не получилось – Excel упорно уверял меня, что все значения разные.
В конце концов я сдался и сделал то, что нужно было сделать в самом начале – определить, какой же именно элемент (или элементы) справочника модель данных считает дубликатом.
Я создал простую таблицу, в которую поместил список [SKU Name], и во второй столбец поместил тот же [SKU Name], изменив у него вычисление на подсчет значений.
Бинго! Отсортировав второй столбец по уменьшению, я, наконец, увидел злосчастную SKU:
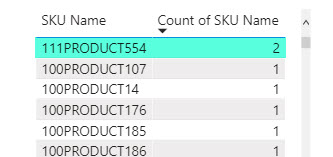
Осталось только понять, почему же эта SKU считается дубликатом в модели, но не обнаруживается как таковой в Power Query и Excel.
Скопировав название SKU, я вернулся в Power Query и отфильтровал многократно очищенный от непечатаемых символов и дубликатов справочник по этому значению.
Угадаете результат? Правильно, я получил одну строку. Никаких дубликатов.

Я на некоторое время завис, не понимая, что делать дальше. «Вы суслика видите? – Нет. – А он есть.»
И тут меня посетила гениальная идея: вместо фильтра столбца по самому значению SKU, я решил проверить, что мне даст фильтр «Текст содержит…»
Вот они, красавицы:

В общем, опустив еще несколько непечатных выражений, резюмирую: эти две строки отличаются лишним пробелом в конце в одной из строк.
Еще немного экспериментов показали:
Вы знаете, вообще-то предупреждать надо… Я перерыл кучу документации и нашел только несколько отсылок к кубам Analysis Services, а также несколько сообщений на форумах, подтверждающих: так задумано, и вряд ли будет изменено в ближайшем времени. Может быть, кто-то сможет найти ссылку на место в документации, где об этом говорится?
Опытные товарищи подсказали, что это поведение соответствует стандарту ANSI SQL. Возможно, это и так, но мне, как пришедшему из мира Excel, это неведомо.
Справиться с этой проблемой можно так:
Text.Trim (или, если вам дороги начальные пробелы, функции Text.TrimEnd) перед удалением дубликатов. Это можно сделать и через интерфейс, кнопками, на вкладке Transform: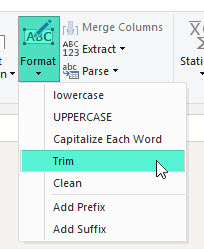
(string)=> if Text.End( string, 1 )=" " then string &"." else stringУдачи, и глядите в оба!
Follow me: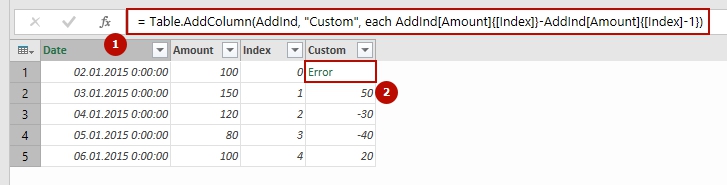
Эта статья – перевод моего первого поста в этом блоге, который был опубликован 5 ноября 2015 года на английском языке. К моему удивлению, этот пост – самый популярный, за это время он набрал почти 21000 просмотров. С небольшими стилистическими правками публикую его на русском языке. В переводе помогал мой сын Дмитрий, за что ему отдельное спасибо.
Power Query – это мощный инструмент, способный на большее, чем просто брать данные из источника и переносить их в таблицу или Power Pivot. Данные можно очищать и преобразовывать множеством способов, но есть некоторые действия, привычные для Excel, которые не так удобно делать в Power Query.
Например, что, если мне нужна относительная ссылка на конкретную ячейку в таблице Power Query – значение из определённой строки в определённом столбце? Или ссылка на значение в определённом столбце на четыре строки выше? В Excel очевидно, как это сделать: нужно просто указать на нужное значение мышкой, убедиться, что из ссылки к строке убран знак “$” (знак абсолютной ссылки), и всё. Но в Power Query я не могу так просто это сделать.
Но всё же решение, хотя и непрямое, существует.
Прежде всего давайте выясним, как можно получить доступ к конкретному значению из таблицы Power Query.
Простейший способ понять адресацию в Power Query, по-моему, анализировать код шагов.
Допустим, у нас есть простая таблица из двух столбцов: даты (Date) и количества (Amount). В ней пять строк, и в первом столбце стоят, как ни странно, даты, во втором – какие-то значения:
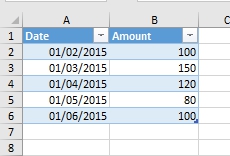
Исходные данные
Мы хотим получить значение из ячейки B4, а именно 120. Continue Reading →Follow me: ![]()
![]()
![]()
![]()
Недавно мне нужно было сделать очень простую операцию в Power Query. В столбце с числами нужно было выполнить проверку “значение меньше N” и в новом столбце вывести соответствующий текст. Функция дополнительного столбца выглядит примерно так:
|
1 |
= if [Values] < 5 then "A" else "B" |
На самом деле некоторые значения – null (то есть пустые):
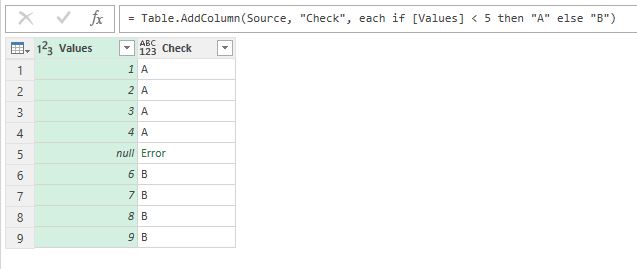
Данные содержат null и в результате сравнения возникает ошибка
И такая простая операция возвращает ошибку для этих значений!
Почему? Есть некоторая ловушка, спрятанная в глубинах документации (а именно на странице 67 PDF-файла “Power Query Formula Language Specification (October 2016)”, который можно найти тут.
Continue Reading →Follow me: ![]()
![]()
![]()
![]()
Иногда, особенно во время работы с таблицами-календарями, нам необходимо определить номер недели по ISO. К сожалению, “родной” функции для этого в Power Query или в Power BI нет, и для получения нужного результата приходится писать свою.
Спасибо Catherine Monier, Microsoft Excel MVP, за ссылку на готовую функцию для Power Query “Date to ISO Week”. Также по этой ссылке можно найти и обратную функцию, переводящую даты формата 2017-W02-7 в обычную дату:
Написать такую функцию не очень сложно, но приятно же, когда это уже сделали за вас? 🙂Follow me: ![]()
![]()
![]()
![]()

Эта статья о работе надстройки Power Query к Excel 2010 и Excel 2013, редактора запросов Power BI и группы команд “Get & Transform” (“Получить и преобразовать”) в Excel 2016. Надеюсь, когда-нибудь эта чехарда закончится и мы сможем говорить просто Power Query.
Результатом вычисления запроса в Power Query является единственное значение. Как правило, речь идет о таблице, которую мы затем выгружаем на лист или в модель данных в Excel и Power BI. Это же требование относится также и к любым другим выражениям, вычисляемым Power Query, например, встроенным или пользовательским функциям, полям записей, записям в целом, и т.д.
Однако можно легко представить себе ситуацию, когда нам нужно, чтобы функция или запрос вместе с основным результатом вернули и другую информацию – дополнительный или промежуточный результат вычисления.
Представьте, что в процессе сложных преобразований запроса Query1 последним шагом под названием ResultTable мы получили нужный результат (таблицу), которую мы хотим загрузить в модель данных. Одним из промежуточных шагов в нашем запросе был расчет какой-то величины ValueX , и мы хотели бы использовать ее в других выражениях или запросах:
|
1 2 3 4 5 6 7 8 9 |
// Query1 let Source = …, // источник данных …, // какие-то шаги ValueX = …, // промежуточный результат …, // еще какие-то шаги ResultTable = … // получаем таблицу-результат in ResultTable // но она не содержит в себе данные для получения ValueX |
Нам в итоге нужен и ValueX , и, конечно же, ResultTable .
У нас есть как минимум три способа это сделать: Continue Reading →Follow me: ![]()
![]()
![]()
![]()
или “Как же все-таки работает List.Generate?”
List.Generate – одна из функций языка “M” (язык Power Query aka “Get & Transform” для Excel и редактора запросов Power BI), используемая для создания списков (lists ) по заданным правилам. В отличие от других генераторов списков (например, List.Repeat или List.Dates), правила и алгоритм генерации очередного элемента может быть практически любым, что позволяет использовать List.Generate для решения достаточно сложных задач.
Несмотря на то, что есть несколько отличных постов, описывающих использование этой функции (например, Chris Webb, Gil Raviv, PowerPivotPro, KenR), мне всегда не хватало более понятного описания – “как же это всё работает?!” или “Почему оно не работает?” и, наконец, “Что вообще имели ввиду разработчики?”
Как обычно, справка MSDN крайне лаконична:
Создает список значений с четырьмя функциями, которые создают начальное значение initial , проверяют выполнение условия condition и в случае успеха выбирают результат и формируют следующее значение next . Необязательный параметр selector может также быть указан.
Скажите, вы хотели бы использовать необязательный параметр selector ? Точно? Уверены?
Можно было бы списать на несовершенство перевода, но я вас уверяю, по-английски не лучше:
Generates a list of values given four functions that generate the initial value initial , test against a condition condition , and if successful select the result and generate the next value next . An optional parameter, selector , may also be specified.
Хотя на самом деле есть еще и краткое описание функции, которое выглядит чуть более внятно:
Создает список с указанием функции начального значения, функции условия, следующей функции и необязательной функции для преобразования значений.
По крайней мере, одно очевидно: функция принимает 4 аргумента, все 4 имеют тип function:
|
1 |
List.Generate(initial as function, condition as function, next as function, optional selector as nullable function) as list |
На самом деле функция List.Generate использует достаточно простой алгоритм. В процессе генерации каждого элемента списка функция рассчитывает значение (назовем его CurrentValue), которое модифицируется и передается от одной функции-аргумента к другой в следующем цикле:
Как можно увидеть из этого описания, важным отличием List.Generate от других функций-итераторов языка M является то, что практически все остальные работают по принципу For Each…Next (то есть ограничены заданным списком перебора), в то время как List.Generate использует другую логику – Do While…Loop . Соответственно, количество элементов в созданном списке ограничивается только выполнением некоего условия.
Если записать приведенный выше алгоритм на каком-нибудь привычном (не функциональном) языке, то он мог бы выглядеть примерно так:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Dim NewList As New List CurrentValue = initial() Do While condition(CurrentValue) If selector = null Then NewList.Add(CurrentValue) Else NewList.Add(selector(CurrentValue)) End If CurrentValue = next(CurrentValue) Loop |
При этом:
Например, если вы создаете список в процессе работы с каким-либо API (например, в функциях initial и next посылаете запросы на подготовку или получение отчетов), имейте ввиду следующее:
Удобнее всего, когда initial и next возвращают тип record . Это сильно упрощает добавление счётчиков и дополнительных аргументов для этих функций (одно из полей записи – основные данные, другое – счетчик, третье – какой-то еще параметр, используемый для генератора элементов, и так далее).
В итоге, List.Generate – это очень мощный по возможностям инструмент, хотя и немного тяжелый в освоении . Надеюсь, после этой статьи он стал понятнее и дружелюбнее. 🙂
Follow me: ![]()
![]()
![]()
![]()
Недавно я опубликовал пост о ловушке UsedRange, в которую вы можете попасть при импорте данных с листа Excel в Power Query (вы можете прочесть его тут).
Чтобы добавить возможность импорта в Power Query данных с заданных диапазонов на листе, я создал соответствующие темы на форумах excel.uservoice.com и https://ideas.powerbi.com
Проголосуйте, пожалуйста, за эти улучшения – они могут не только сэкономить вам несколько строк кода, но и спасти от потенциальных ошибок при работе с неструктурированными данными в Excel.
Спасибо!Follow me: ![]()
![]()
![]()
![]()
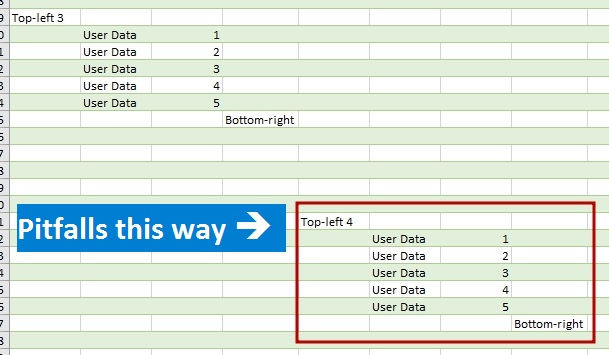
Если вы импортируете данные в Power Query или Power BI из файла Excel, обращаясь к листу целиком, будьте осторожны – вас может поджидать ловушка.
При подключении к стороннему файлу Excel нам доступны три варианта извлечения данных:
В первом случае объект «Таблица» представляет собой уже структурированные данные с заголовками столбцов, которые впоследствии автоматически трансформируются в таблицы. Во втором случае Power Query снабдит именованный диапазон автоматическими заголовками (“Column1”, “Column2” и так далее), и дальнейшая обработка не отличается от импортированных таблиц.
Однако очень часто нужные данные не находятся в форматированной таблице или именованном диапазоне, и преобразовать их в такой вид затруднительно. Причин может быть много, например, необходимо сохранить форматирование (объединение ячеек теряется при преобразовании в таблицу), либо файлов слишком много для ручного преобразования в нужный формат.
К счастью, Power Query может получить данные с листа целиком. Для того чтобы получить данные из неразмеченного листа, никаких особых действий предпринимать не нужно: подключаемся к файлу, находим нужный лист (в столбце [Kind] он будет иметь значение “Sheet”) и получаем данные путем обращения к его содержимому в столбце [Data]:
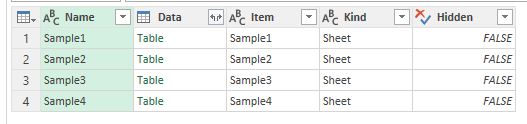
Листы Excel доступны в качестве источника наравне с таблицами и именованными диапазонами
Однако возникает вопрос, какие данные попадут в таблицу для этого листа? На листе Excel 17 179 869 184 ячеек (16 384 столбцов и 1 048 576 строк). Если бы Power Query пытался загрузить их все, это привело бы к безнадежным «тормозам» при импорте данных таким образом. Однако мы можем убедиться, что обычно количество строк и столбцов примерно соответствует заполненным.
Как же Power Query определяет нужный диапазон данных? Ответ может быть достаточно очевиден, если у вас есть достаточный опыт программирования на VBA и вы хорошо знакомы с объектной моделью Excel (и ответ вас не обрадует). Continue Reading →Follow me: ![]()
![]()
![]()
![]()