Особенность загрузки текстовых столбцов в Power BI и PowerPivot, или Как найти дубликаты там, где их нет
Проблема
На днях я провел несколько увлекательных часов, пытаясь найти причину, по которой Power BI отказывался строить связь «один-ко-многим» между двумя таблицами – справочником и таблицей фактов. Эта короткая история в очередной раз говорит нам: «Век живи – век учись»
Ошибка, на которую указывал Power BI, звучит приблизительно так: «невозможно установить связь – как минимум один из столбцов, участвующих в связи, должен содержать уникальные данные»
Связь между двумя столбцами должна была строиться по текстовому полю [SKU Name], содержащему названия SKU (я понимаю, что это не лучший вариант, но таковы условия проекта), источник данных – таблицы Excel.
Так как в таблице фактов значения не предполагали уникальности, было понятно, что нужно искать проблему именно в справочнике, где они должны быть уникальными.
Вы суслика видите?..
Обнаружить дубликаты в редакторе запросов Power Query не получалось ну совсем никак:
- Удаление дубликатов из столбца
[SKU Name]не изменило количество строк. - Помня, что модель данных и DAX не различает регистр (в отличие от Power Query), я перевел значения столбца в верхний регистр и снова удалил дубликаты. Не помогло.
- Предположив, что в тексте могут случайно встретиться непечатаемые символы, я применил очистку (
Text.Clean) значений столбца. Это тоже не помогло удалить дубликаты, но зато увеличилось количество звучащих в моем домашнем офисе непечатных выражений. - Я подключил тяжелую артиллерию – вместо простого удаления дубликатов при помощи кнопки в интерфейсе я видоизменил формулу этого шага, явно указав игнорирование регистра (ну мало ли) и язык проверки дубликатов:
Table.Distinct(Table, {{“SKU Name”, Comparer.FromCulture(“en-us”, true)}}). Не помогло…
Обнаружить дубликаты в источнике (файлах Excel) тоже не получилось – Excel упорно уверял меня, что все значения разные.
В конце концов я сдался и сделал то, что нужно было сделать в самом начале – определить, какой же именно элемент (или элементы) справочника модель данных считает дубликатом.
Я создал простую таблицу, в которую поместил список [SKU Name], и во второй столбец поместил тот же [SKU Name], изменив у него вычисление на подсчет значений.
Бинго! Отсортировав второй столбец по уменьшению, я, наконец, увидел злосчастную SKU:
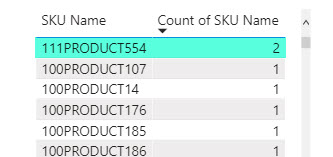
Осталось только понять, почему же эта SKU считается дубликатом в модели, но не обнаруживается как таковой в Power Query и Excel.
Скопировав название SKU, я вернулся в Power Query и отфильтровал многократно очищенный от непечатаемых символов и дубликатов справочник по этому значению.
Угадаете результат? Правильно, я получил одну строку. Никаких дубликатов.

Я на некоторое время завис, не понимая, что делать дальше. «Вы суслика видите? – Нет. – А он есть.»
Не дубликат я!
И тут меня посетила гениальная идея: вместо фильтра столбца по самому значению SKU, я решил проверить, что мне даст фильтр «Текст содержит…»
Вот они, красавицы:

В общем, опустив еще несколько непечатных выражений, резюмирую: эти две строки отличаются лишним пробелом в конце в одной из строк.
Еще немного экспериментов показали:
- При загрузке в модель данных из строк удаляются концевые пробелы.
- Начальные пробелы и лишние внутренние пробелы не удаляются
- PowerPivot в Excel ведет себя точно также, как и Power BI
- Обычная сводная таблица в Excel уважает концевые пробелы и не удаляет их.
Вы знаете, вообще-то предупреждать надо… Я перерыл кучу документации и нашел только несколько отсылок к кубам Analysis Services, а также несколько сообщений на форумах, подтверждающих: так задумано, и вряд ли будет изменено в ближайшем времени. Может быть, кто-то сможет найти ссылку на место в документации, где об этом говорится?
Опытные товарищи подсказали, что это поведение соответствует стандарту ANSI SQL. Возможно, это и так, но мне, как пришедшему из мира Excel, это неведомо.
Резюме
Справиться с этой проблемой можно так:
- Если такие строки действительно дубликаты, они прекрасно удаляются за счет применения функции
Text.Trim(или, если вам дороги начальные пробелы, функцииText.TrimEnd) перед удалением дубликатов. Это можно сделать и через интерфейс, кнопками, на вкладке Transform:
- Если эти строки принципиально различаются и вы не хотите считать их дубликатами, то нужно сделать очень простую вещь – добавить какой-то символ к строке, заканчивающейся на пробел.
Например, можно (в новом столбце или при трансформации столбца) добавить точку в конец такой строки при помощи простой функции:(string)=> if Text.End( string, 1 )=" " then string &"." else string - Если вы не против добавить символ ко всем строкам, то можно просто добавить суффикс ко всем значениям столбца – через то же меню, что и на картинке выше, пункт “Add Suffix”.
Удачи, и глядите в оба!
Follow me: