Faster Than Joins! Power Query Record as Dictionary: Part 3
Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →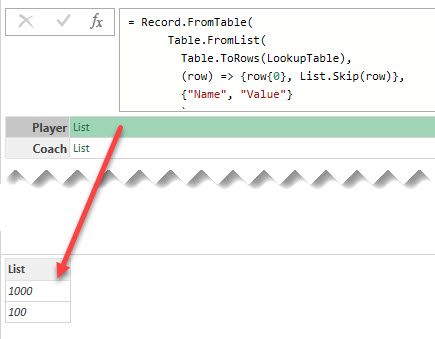
Using the Record.FieldOrDefault function in Power Query to lookup values from dictionary record and handle missing keys
Continue Reading →На днях я провел несколько увлекательных часов, пытаясь найти причину, по которой Power BI отказывался строить связь «один-ко-многим» между двумя таблицами – справочником и таблицей фактов. Эта короткая история в очередной раз говорит нам: «Век живи – век учись»
Ошибка, на которую указывал Power BI, звучит приблизительно так: «невозможно установить связь – как минимум один из столбцов, участвующих в связи, должен содержать уникальные данные»
Связь между двумя столбцами должна была строиться по текстовому полю [SKU Name], содержащему названия SKU (я понимаю, что это не лучший вариант, но таковы условия проекта), источник данных – таблицы Excel.
Так как в таблице фактов значения не предполагали уникальности, было понятно, что нужно искать проблему именно в справочнике, где они должны быть уникальными.
Обнаружить дубликаты в редакторе запросов Power Query не получалось ну совсем никак:
[SKU Name] не изменило количество строк.Text.Clean) значений столбца. Это тоже не помогло удалить дубликаты, но зато увеличилось количество звучащих в моем домашнем офисе непечатных выражений.Table.Distinct(Table, {{“SKU Name”, Comparer.FromCulture(“en-us”, true)}}). Не помогло…Обнаружить дубликаты в источнике (файлах Excel) тоже не получилось – Excel упорно уверял меня, что все значения разные.
В конце концов я сдался и сделал то, что нужно было сделать в самом начале – определить, какой же именно элемент (или элементы) справочника модель данных считает дубликатом.
Я создал простую таблицу, в которую поместил список [SKU Name], и во второй столбец поместил тот же [SKU Name], изменив у него вычисление на подсчет значений.
Бинго! Отсортировав второй столбец по уменьшению, я, наконец, увидел злосчастную SKU:
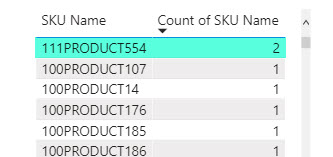
Осталось только понять, почему же эта SKU считается дубликатом в модели, но не обнаруживается как таковой в Power Query и Excel.
Скопировав название SKU, я вернулся в Power Query и отфильтровал многократно очищенный от непечатаемых символов и дубликатов справочник по этому значению.
Угадаете результат? Правильно, я получил одну строку. Никаких дубликатов.

Я на некоторое время завис, не понимая, что делать дальше. «Вы суслика видите? – Нет. – А он есть.»
И тут меня посетила гениальная идея: вместо фильтра столбца по самому значению SKU, я решил проверить, что мне даст фильтр «Текст содержит…»
Вот они, красавицы:

В общем, опустив еще несколько непечатных выражений, резюмирую: эти две строки отличаются лишним пробелом в конце в одной из строк.
Еще немного экспериментов показали:
Вы знаете, вообще-то предупреждать надо… Я перерыл кучу документации и нашел только несколько отсылок к кубам Analysis Services, а также несколько сообщений на форумах, подтверждающих: так задумано, и вряд ли будет изменено в ближайшем времени. Может быть, кто-то сможет найти ссылку на место в документации, где об этом говорится?
Опытные товарищи подсказали, что это поведение соответствует стандарту ANSI SQL. Возможно, это и так, но мне, как пришедшему из мира Excel, это неведомо.
Справиться с этой проблемой можно так:
Text.Trim (или, если вам дороги начальные пробелы, функции Text.TrimEnd) перед удалением дубликатов. Это можно сделать и через интерфейс, кнопками, на вкладке Transform: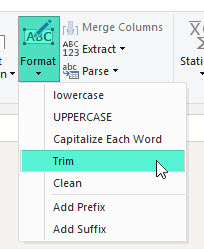
(string)=> if Text.End( string, 1 )=" " then string &"." else stringУдачи, и глядите в оба!
Follow me: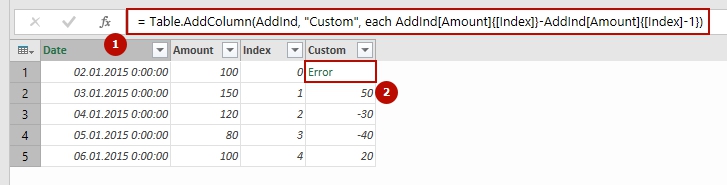
Эта статья – перевод моего первого поста в этом блоге, который был опубликован 5 ноября 2015 года на английском языке. К моему удивлению, этот пост – самый популярный, за это время он набрал почти 21000 просмотров. С небольшими стилистическими правками публикую его на русском языке. В переводе помогал мой сын Дмитрий, за что ему отдельное спасибо.
Power Query – это мощный инструмент, способный на большее, чем просто брать данные из источника и переносить их в таблицу или Power Pivot. Данные можно очищать и преобразовывать множеством способов, но есть некоторые действия, привычные для Excel, которые не так удобно делать в Power Query.
Например, что, если мне нужна относительная ссылка на конкретную ячейку в таблице Power Query – значение из определённой строки в определённом столбце? Или ссылка на значение в определённом столбце на четыре строки выше? В Excel очевидно, как это сделать: нужно просто указать на нужное значение мышкой, убедиться, что из ссылки к строке убран знак “$” (знак абсолютной ссылки), и всё. Но в Power Query я не могу так просто это сделать.
Но всё же решение, хотя и непрямое, существует.
Прежде всего давайте выясним, как можно получить доступ к конкретному значению из таблицы Power Query.
Простейший способ понять адресацию в Power Query, по-моему, анализировать код шагов.
Допустим, у нас есть простая таблица из двух столбцов: даты (Date) и количества (Amount). В ней пять строк, и в первом столбце стоят, как ни странно, даты, во втором – какие-то значения:
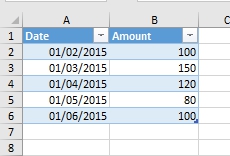
Исходные данные
Мы хотим получить значение из ячейки B4, а именно 120. Continue Reading →Follow me: ![]()
![]()
![]()
![]()

Эта статья о работе надстройки Power Query к Excel 2010 и Excel 2013, редактора запросов Power BI и группы команд “Get & Transform” (“Получить и преобразовать”) в Excel 2016. Надеюсь, когда-нибудь эта чехарда закончится и мы сможем говорить просто Power Query.
Результатом вычисления запроса в Power Query является единственное значение. Как правило, речь идет о таблице, которую мы затем выгружаем на лист или в модель данных в Excel и Power BI. Это же требование относится также и к любым другим выражениям, вычисляемым Power Query, например, встроенным или пользовательским функциям, полям записей, записям в целом, и т.д.
Однако можно легко представить себе ситуацию, когда нам нужно, чтобы функция или запрос вместе с основным результатом вернули и другую информацию – дополнительный или промежуточный результат вычисления.
Представьте, что в процессе сложных преобразований запроса Query1 последним шагом под названием ResultTable мы получили нужный результат (таблицу), которую мы хотим загрузить в модель данных. Одним из промежуточных шагов в нашем запросе был расчет какой-то величины ValueX , и мы хотели бы использовать ее в других выражениях или запросах:
|
1 2 3 4 5 6 7 8 9 |
// Query1 let Source = …, // источник данных …, // какие-то шаги ValueX = …, // промежуточный результат …, // еще какие-то шаги ResultTable = … // получаем таблицу-результат in ResultTable // но она не содержит в себе данные для получения ValueX |
Нам в итоге нужен и ValueX , и, конечно же, ResultTable .
У нас есть как минимум три способа это сделать: Continue Reading →Follow me: ![]()
![]()
![]()
![]()
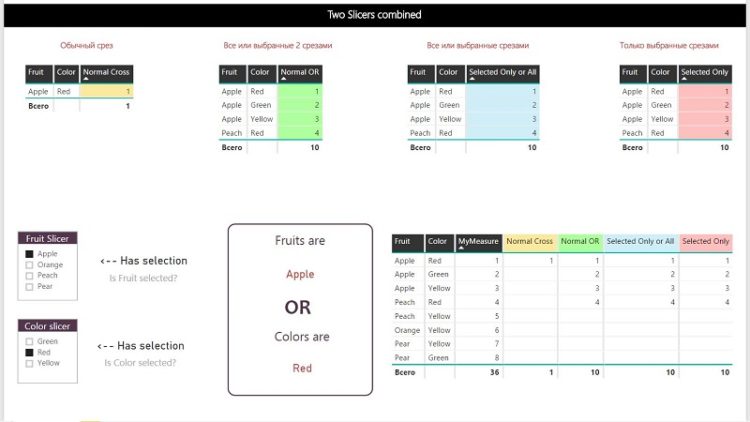
В стандартном режиме несколько срезов в Power BI работают по принципу «И», то есть пересечения примененных фильтров. Мы выбираем на одном срезе «Яблоки», на другом цвет «Красный», и получаем меры, рассчитанные только для красных яблок. Зеленые яблоки будут проигнорированы.
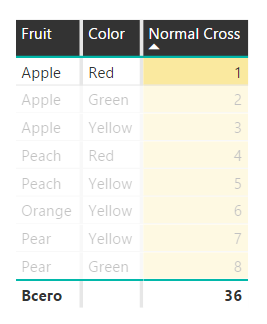
Обычный срез: красные яблоки
Периодически (хоть и нечасто) возникает другая задача: как заставить срезы работать по принципу «ИЛИ», то есть учитывать в мере значения обоих срезов? Например, получить одновременно все зеленые фрукты и все яблоки? Все желтое или грушевидное?
Более практичный пример: товарная позиция может быть помечена в базе как складская (за это отвечает свойство «Складская»), одновременно она помечена как плановая (за это отвечает другое свойство, «Плановая»). Для расчетов нас интересуют позиции, которые могут являться, к примеру, складскими ИЛИ плановыми (то есть у них может быть установлено либо одно из этих свойств, либо оба). Но при использовании двух обычных срезов отбор по свойству “Складская” = “Да” приведет к тому, что прочие строки будут отфильтрованы, даже если у них свойство «Плановая» тоже установлено срезом в значение «Да».
Множество интересных способов получить желаемый результат можно почерпнуть в статье гуру DAX Альберто Феррари и Марко Руссо («итальянцев»). Обычно примеры таких мер используют так называемые «прямые» фильтры – когда проводится сравнение с жестко заданным значением. Стандартное решение для таких мер следующее:
Continue Reading →Follow me: ![]()
![]()
![]()
![]()
Недавно я опубликовал пост о ловушке UsedRange, в которую вы можете попасть при импорте данных с листа Excel в Power Query (вы можете прочесть его тут).
Чтобы добавить возможность импорта в Power Query данных с заданных диапазонов на листе, я создал соответствующие темы на форумах excel.uservoice.com и https://ideas.powerbi.com
Проголосуйте, пожалуйста, за эти улучшения – они могут не только сэкономить вам несколько строк кода, но и спасти от потенциальных ошибок при работе с неструктурированными данными в Excel.
Спасибо!Follow me: ![]()
![]()
![]()
![]()
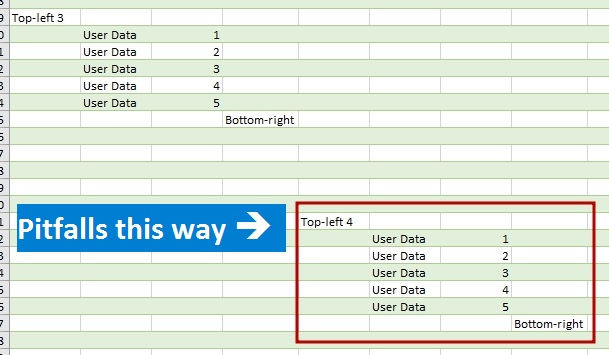
Если вы импортируете данные в Power Query или Power BI из файла Excel, обращаясь к листу целиком, будьте осторожны – вас может поджидать ловушка.
При подключении к стороннему файлу Excel нам доступны три варианта извлечения данных:
В первом случае объект «Таблица» представляет собой уже структурированные данные с заголовками столбцов, которые впоследствии автоматически трансформируются в таблицы. Во втором случае Power Query снабдит именованный диапазон автоматическими заголовками (“Column1”, “Column2” и так далее), и дальнейшая обработка не отличается от импортированных таблиц.
Однако очень часто нужные данные не находятся в форматированной таблице или именованном диапазоне, и преобразовать их в такой вид затруднительно. Причин может быть много, например, необходимо сохранить форматирование (объединение ячеек теряется при преобразовании в таблицу), либо файлов слишком много для ручного преобразования в нужный формат.
К счастью, Power Query может получить данные с листа целиком. Для того чтобы получить данные из неразмеченного листа, никаких особых действий предпринимать не нужно: подключаемся к файлу, находим нужный лист (в столбце [Kind] он будет иметь значение “Sheet”) и получаем данные путем обращения к его содержимому в столбце [Data]:
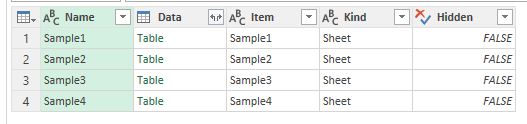
Листы Excel доступны в качестве источника наравне с таблицами и именованными диапазонами
Однако возникает вопрос, какие данные попадут в таблицу для этого листа? На листе Excel 17 179 869 184 ячеек (16 384 столбцов и 1 048 576 строк). Если бы Power Query пытался загрузить их все, это привело бы к безнадежным «тормозам» при импорте данных таким образом. Однако мы можем убедиться, что обычно количество строк и столбцов примерно соответствует заполненным.
Как же Power Query определяет нужный диапазон данных? Ответ может быть достаточно очевиден, если у вас есть достаточный опыт программирования на VBA и вы хорошо знакомы с объектной моделью Excel (и ответ вас не обрадует). Continue Reading →Follow me: ![]()
![]()
![]()
![]()
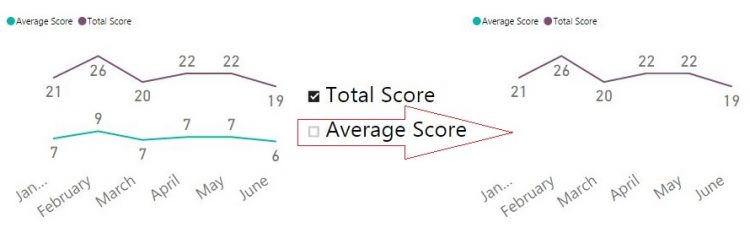
Несколько дней назад мой клиент поинтересовался, возможно ли динамически (при помощи среза) изменить набор рядов, отображаемых на диаграмме Power BI. Мой первый (инстинктивный) ответ был “Да, конечно, вы можете использовать срез, чтобы выбрать отображаемые на диаграмме ряды, просто поместите нужный столбец в срез”. Но затем клиент уточнил: выбирать на диаграмме нужно разные меры, а не разные категории из столбца. Второй (не менее инстинктивный) ответ был “Нет, это невозможно. Срез может только фильтровать столбец, и поместить меры в срез нельзя”.
Однако после некоторого обсуждения я засомневался, действительно ли это невозможно. Если мы поместим меру в область значений (“Value”) диаграммы, она будет показана как ряд (например, какая-то мера [Total Amount]). А что на самом деле нужно моему клиенту? Он хочет выбрать какие-то значения на срезе и, если некоторое значение выбрано, показать соответствующую меру. Если значение не выбрано, то не показывать эту меру.
На самом деле элементы среза это уникальные значения какого-то столбца. Срез применяет фильтр к этому столбцу. Можем мы понять, что столбец отфильтрован? Да, конечно, мы можем это сделать при помощи формул DAX. Если нужное значение выбрано, то мы должны показать меру как ряд на диаграмме. Так как эта мера уже находится в области значений диаграммы, то нам нужно, попросту говоря, “ничего не делать”. Собственно, нам необходимо только как-то спрятать меру, если нужное значение не выбрано на срезе.
Continue Reading →Follow me: ![]()
![]()
![]()
![]()