На днях я провел несколько увлекательных часов, пытаясь найти причину, по которой Power BI отказывался строить связь «один-ко-многим» между двумя таблицами – справочником и таблицей фактов. Эта короткая история в очередной раз говорит нам: «Век живи – век учись»
Ошибка, на которую указывал Power BI, звучит приблизительно так: «невозможно установить связь – как минимум один из столбцов, участвующих в связи, должен содержать уникальные данные»
Связь между двумя столбцами должна была строиться по текстовому полю [SKU Name], содержащему названия SKU (я понимаю, что это не лучший вариант, но таковы условия проекта), источник данных – таблицы Excel.
Так как в таблице фактов значения не предполагали уникальности, было понятно, что нужно искать проблему именно в справочнике, где они должны быть уникальными.
Вы суслика видите?..
Обнаружить дубликаты в редакторе запросов Power Query не получалось ну совсем никак:
Удаление дубликатов из столбца [SKU Name] не изменило количество строк.
Помня, что модель данных и DAX не различает регистр (в отличие от Power Query), я перевел значения столбца в верхний регистр и снова удалил дубликаты. Не помогло.
Предположив, что в тексте могут случайно встретиться непечатаемые символы, я применил очистку (Text.Clean) значений столбца. Это тоже не помогло удалить дубликаты, но зато увеличилось количество звучащих в моем домашнем офисе непечатных выражений.
Я подключил тяжелую артиллерию – вместо простого удаления дубликатов при помощи кнопки в интерфейсе я видоизменил формулу этого шага, явно указав игнорирование регистра (ну мало ли) и язык проверки дубликатов: Table.Distinct(Table, {{“SKU Name”, Comparer.FromCulture(“en-us”, true)}}). Не помогло…
Обнаружить дубликаты в источнике (файлах Excel) тоже не получилось – Excel упорно уверял меня, что все значения разные.
В конце концов я сдался и сделал то, что нужно было сделать в самом начале – определить, какой же именно элемент (или элементы) справочника модель данных считает дубликатом.
Я создал простую таблицу, в которую поместил список [SKU Name], и во второй столбец поместил тот же [SKU Name], изменив у него вычисление на подсчет значений.
Бинго! Отсортировав второй столбец по уменьшению, я, наконец, увидел злосчастную SKU:
Вот он, исчадие рода Баскервилей SKU!
Осталось только понять, почему же эта SKU считается дубликатом в модели, но не обнаруживается как таковой в Power Query и Excel.
Скопировав название SKU, я вернулся в Power Query и отфильтровал многократно очищенный от непечатаемых символов и дубликатов справочник по этому значению.
Угадаете результат? Правильно, я получил одну строку. Никаких дубликатов.
Здесь должно быть две строки, но видна только одна
Я на некоторое время завис, не понимая, что делать дальше. «Вы суслика видите? – Нет. – А он есть.»
Не дубликат я!
И тут меня посетила гениальная идея: вместо фильтра столбца по самому значению SKU, я решил проверить, что мне даст фильтр «Текст содержит…»
Вот они, красавицы:
Дубликаты нашлись. Осталось понять, почему они не удалились
В общем, опустив еще несколько непечатных выражений, резюмирую: эти две строки отличаются лишним пробелом в конце в одной из строк.
Еще немного экспериментов показали:
При загрузке в модель данных из строк удаляются концевые пробелы.
Начальные пробелы и лишние внутренние пробелы не удаляются
PowerPivot в Excel ведет себя точно также, как и Power BI
Обычная сводная таблица в Excel уважает концевые пробелы и не удаляет их.
Вы знаете, вообще-то предупреждать надо… Я перерыл кучу документации и нашел только несколько отсылок к кубам Analysis Services, а также несколько сообщений на форумах, подтверждающих: так задумано, и вряд ли будет изменено в ближайшем времени. Может быть, кто-то сможет найти ссылку на место в документации, где об этом говорится?
Опытные товарищи подсказали, что это поведение соответствует стандарту ANSI SQL. Возможно, это и так, но мне, как пришедшему из мира Excel, это неведомо.
Резюме
Справиться с этой проблемой можно так:
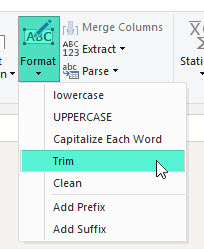
Если такие строки действительно дубликаты, они прекрасно удаляются за счет применения функции Text.Trim (или, если вам дороги начальные пробелы, функции Text.TrimEnd) перед удалением дубликатов. Это можно сделать и через интерфейс, кнопками, на вкладке Transform:
Если эти строки принципиально различаются и вы не хотите считать их дубликатами, то нужно сделать очень простую вещь – добавить какой-то символ к строке, заканчивающейся на пробел. Например, можно (в новом столбце или при трансформации столбца) добавить точку в конец такой строки при помощи простой функции: (string)=> if Text.End( string, 1 )=" " then string &"." else string
Если вы не против добавить символ ко всем строкам, то можно просто добавить суффикс ко всем значениям столбца – через то же меню, что и на картинке выше, пункт “Add Suffix”.
Недавно в чате о Power BI в Telegram был задан вопрос – возможно ли применить для графика Waterfall (каскадная диаграмма, она же «Водопад») нестандартную динамическую сортировку: положительные значения показываются по убыванию, а отрицательные наоборот, по возрастанию (то есть, сначала самые большие по модулю отрицательные значения, затем минуса поменьше и самые мелкие – в конце).
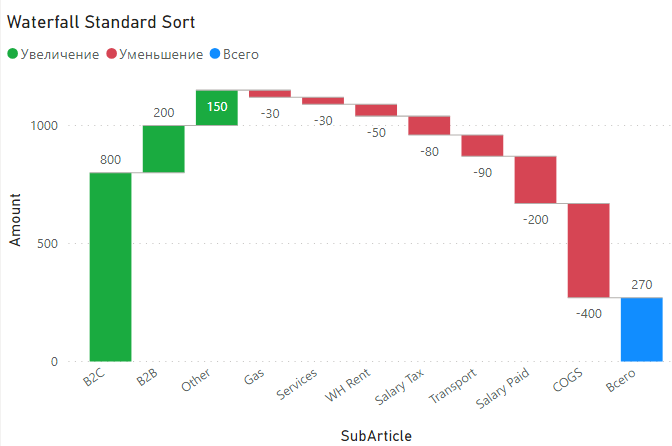
В итоге из такого графика:
Обычная сортировка каскадной диаграммы
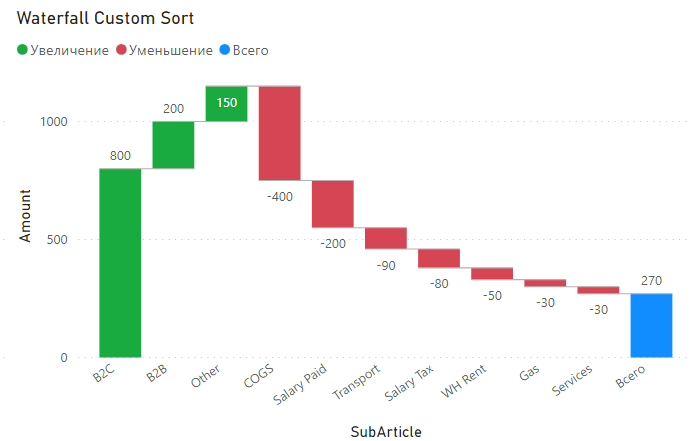
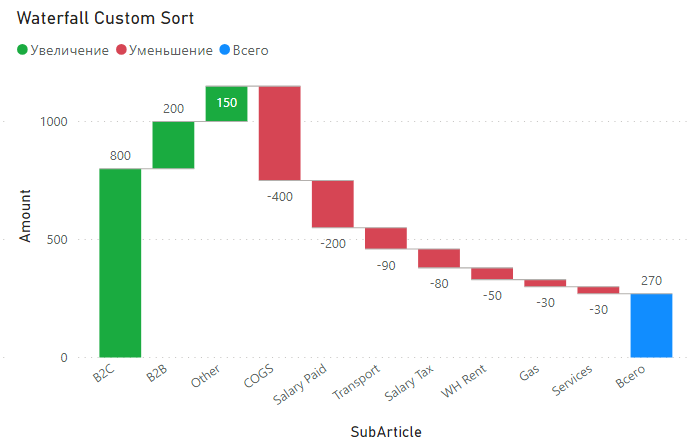
Нужно получить вот такой:
Нестандартная сортировка
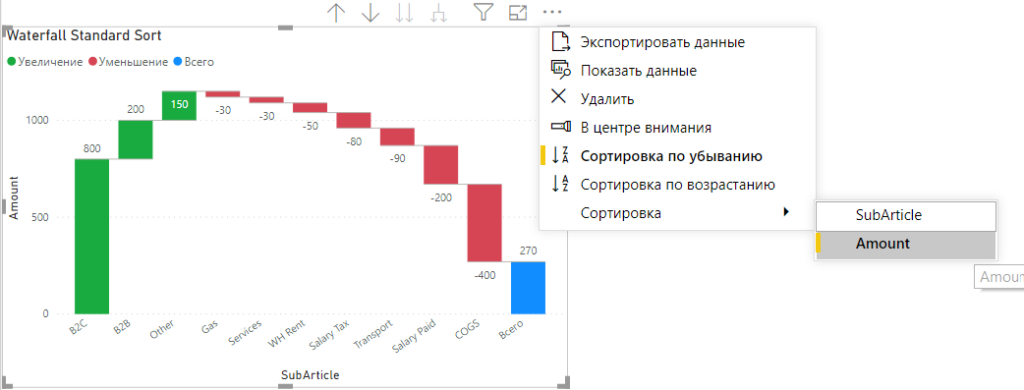
Стандартными средствами мы можем сортировать Waterfall только
по возрастанию или убыванию, по обычным правилам (настроить и проверить
сортировку можно нажав на три точки в правом верхнем углу визуала):
Настройка сортировки в каскадной диаграмме Power BI
Нам же нужно сделать так, чтобы:
Можно было применить нестандартную сортировку;
Она должна быть динамической, то есть
реагировать на фильтры (например, по дате)
Решение этой задачи делится на две подзадачи:
Найти способ применить пользовательскую
сортировку
Определить и реализовать алгоритм сортировки
Можем ли мы применить пользовательскую сортировку?
Первая подзадача в случае визуального элемента Waterfall (каскадная
диаграмма) решается просто: мы можем использовать для сортировки любые поля,
помещенные в одну из областей визуального элемента.
У Waterfall таких областей четыре:
Категория
Распределение
Ось Y
Подсказки
Первые две используются для определения значений оси X, третья – для определения
размера столбиков, а вот четвертая используется для вывода информации во
всплывающем окошке при наведении мыши на элемент графика.
Вот ее мы и будем использовать для того, чтобы отсортировать
значения на графике в нужном нам порядке.
Скажу сразу – если бы мы не могли использовать эту область
для сортировки, то и решение было бы кардинально другим, если бы вообще было.
Как задать правило сортировки?
Вспомним, что сортировка должна учитывать возможность
применения пользовательских фильтров, поэтому нам не подойдет вычисляемый
столбец в DAX или Power Query).
То есть, нам нужна мера.
Теперь нам надо придумать, как создать такую формулу,
которая будет давать нам нужный порядок сортировки.
В обновлении Power BI Desktop от 22 июля 2018 появилась новая замечательная возможность – создавать связи “многие-ко-многим” (Many-To-Many, или M2M) между таблицами модели данных. Пока еще в предварительной версии, то есть не работающее в Power BI Service, но очень интересное нововведение.
До этого обновления в Power BI можно было создавать связи только двух видов: “один к одному” и “многие-к-одному“. Новый тип связи появился в связи с введением в пробную эксплуатацию так называемой “композитной”, или “составной”модели, позволяющей использовать в проекте одновременно как источники, подключенные в режиме Direct Query (например, MS SQL Server), так и источники в режиме Import (например, файл Excel), или сразу несколько источников Direct Query. Связи “многие-ко-многим” на текущий момент являются единственным способом связи между источниками, подключенными в разных режимах (DQ и Import), независимо от их фактической кратности.
Однако применение нового типа связи “многие-ко-многим” не ограничивается только рамками композитной модели – такие связи теперь можно устанавливать между любыми таблицами Power BI!
Такой тип связей открывает для разработчика новую степень свободы, если можно так выразиться. Теперь не обязательно создавать промежуточные бридж-таблицы для связывания двух таблиц по неуникальному ключу – можно настроить такую связь напрямую. Это уменьшает количество таблиц и связей между ними, делая модель проще.
Реализация связей “многие-ко-многим” в Power BI сопряжена с рядом ограничений. Сейчас их всего три (они действуют именно для таблиц, связанных таким способом):
Невозможно использовать функцию RELATED для получения данных связанной таблицы (так как связанными могут оказаться несколько строк).
Не создаются пустые строки для группировки строк, отсутствующих в связанной таблице (а также для строк, имеющих Null в столбце связи другой таблицы).
Функция ALL(), примененная к одной из таблиц, не сбрасывает фильтры, примененные к связанной таблице (а, например, в связи “один-ко-многим” функция ALL(Table) сбрасывает все фильтры со столбцов таблицы, в том числе фильтры, примененные к столбцам таблиц, связанных с находящихся на стороне “один”).
Эти ограничения не так очевидны, и неподготовленный аналитик может быть неприятно удивлён неожиданному поведению мер и визуальных элементов.
Достаточно подробно эти ограничения описаны в официальной документации, а мы с Максимом Уваровым практически сразу после выхода обновления записали видео, в котором я постарался подробно рассказать о новом типе связей, его ограничениях и подводных камнях.
Я считаю, что появление составной модели и нового вида связи между таблицами – это крупнейшее изменение в моделировании данных в Power BI после введения двунаправленной фильтрации. И хотя пока этот тип связи вызывает много вопросов, меня однозначно радует всё, что касается новых инструментов подготовки данных и моделирования в Power BI: приятно смотреть, как любимый инструмент развивается и становится всё мощнее и мощнее. А судя по опубликованному roadmap до октября 2018 года, планов относительно развития Power BI у Microsoft очень много. Нет, не так. ОЧЕНЬ МНОГО.Follow me:
Эта статья – перевод моего первого поста в этом блоге, который был опубликован 5 ноября 2015 года на английском языке. К моему удивлению, этот пост – самый популярный, за это время он набрал почти 21000 просмотров. С небольшими стилистическими правками публикую его на русском языке. В переводе помогал мой сын Дмитрий, за что ему отдельное спасибо.
Power Query – это мощный инструмент, способный на большее, чем просто брать данные из источника и переносить их в таблицу или Power Pivot. Данные можно очищать и преобразовывать множеством способов, но есть некоторые действия, привычные для Excel, которые не так удобно делать в Power Query.
Например, что, если мне нужна относительная ссылка на конкретную ячейку в таблице Power Query – значение из определённой строки в определённом столбце? Или ссылка на значение в определённом столбце на четыре строки выше? В Excel очевидно, как это сделать: нужно просто указать на нужное значение мышкой, убедиться, что из ссылки к строке убран знак “$” (знак абсолютной ссылки), и всё. Но в Power Query я не могу так просто это сделать.
Но всё же решение, хотя и непрямое, существует.
Прежде всего давайте выясним, как можно получить доступ к конкретному значению из таблицы Power Query.
Простейший способ понять адресацию в Power Query, по-моему, анализировать код шагов.
Абсолютные ссылки на строки
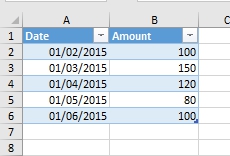
Допустим, у нас есть простая таблица из двух столбцов: даты (Date) и количества (Amount). В ней пять строк, и в первом столбце стоят, как ни странно, даты, во втором – какие-то значения:
Исходные данные
Мы хотим получить значение из ячейки B4, а именно 120. Continue Reading →Follow me:
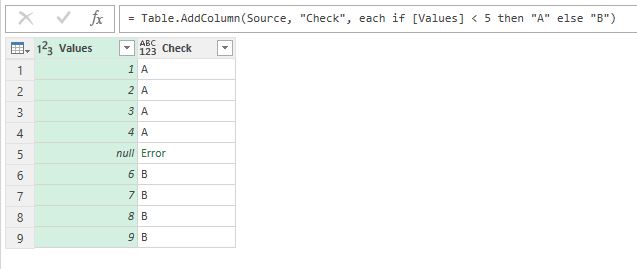
Недавно мне нужно было сделать очень простую операцию в Power Query. В столбце с числами нужно было выполнить проверку “значение меньше N” и в новом столбце вывести соответствующий текст. Функция дополнительного столбца выглядит примерно так:
1
=if[Values]<5then"A"else"B"
На самом деле некоторые значения – null (то есть пустые):
Данные содержат null и в результате сравнения возникает ошибка
И такая простая операция возвращает ошибку для этих значений!
Почему? Есть некоторая ловушка, спрятанная в глубинах документации (а именно на странице 67 PDF-файла “Power Query Formula Language Specification (October 2016)”, который можно найти тут.
Эта статья о работе надстройки Power Query к Excel 2010 и Excel 2013, редактора запросов Power BI и группы команд “Get & Transform” (“Получить и преобразовать”) в Excel 2016. Надеюсь, когда-нибудь эта чехарда закончится и мы сможем говорить просто Power Query.
Результатом вычисления запроса в Power Query является единственное значение. Как правило, речь идет о таблице, которую мы затем выгружаем на лист или в модель данных в Excel и Power BI. Это же требование относится также и к любым другим выражениям, вычисляемым Power Query, например, встроенным или пользовательским функциям, полям записей, записям в целом, и т.д.
Однако можно легко представить себе ситуацию, когда нам нужно, чтобы функция или запрос вместе с основным результатом вернули и другую информацию – дополнительный или промежуточный результат вычисления.
Промежуточные и дополнительные результаты запросов
Представьте, что в процессе сложных преобразований запроса Query1 последним шагом под названием
ResultTable мы получили нужный результат (таблицу), которую мы хотим загрузить в модель данных. Одним из промежуточных шагов в нашем запросе был расчет какой-то величины
ValueX , и мы хотели бы использовать ее в других выражениях или запросах:
M
1
2
3
4
5
6
7
8
9
// Query1
let
Source=…,// источник данных
…,// какие-то шаги
ValueX=…,// промежуточный результат
…,// еще какие-то шаги
ResultTable=…// получаем таблицу-результат
in
ResultTable// но она не содержит в себе данные для получения ValueX
Нам в итоге нужен и
ValueX , и, конечно же,
ResultTable .
У нас есть как минимум три способа это сделать:Continue Reading →Follow me:
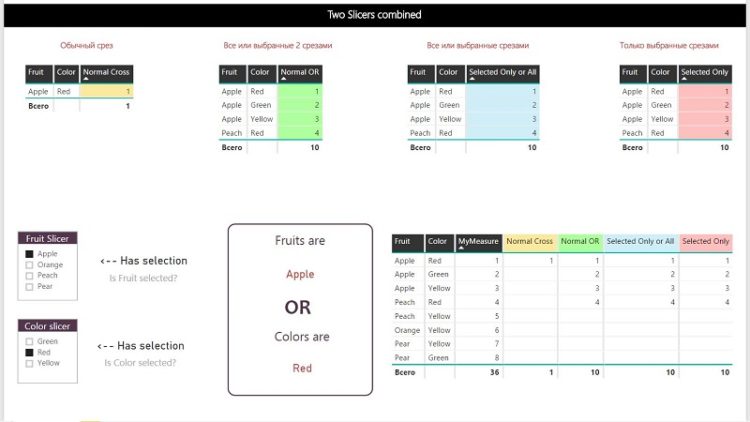
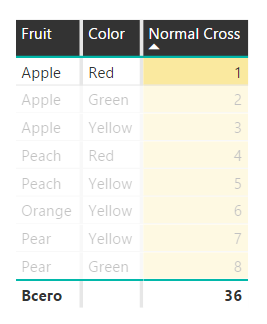
В стандартном режиме несколько срезов в Power BI работают по принципу «И», то есть пересечения примененных фильтров. Мы выбираем на одном срезе «Яблоки», на другом цвет «Красный», и получаем меры, рассчитанные только для красных яблок. Зеленые яблоки будут проигнорированы.
Обычный срез: красные яблоки
Периодически (хоть и нечасто) возникает другая задача: как заставить срезы работать по принципу «ИЛИ», то есть учитывать в мере значения обоих срезов? Например, получить одновременно все зеленые фрукты и все яблоки? Все желтое или грушевидное?
Более практичный пример: товарная позиция может быть помечена в базе как складская (за это отвечает свойство «Складская»), одновременно она помечена как плановая (за это отвечает другое свойство, «Плановая»). Для расчетов нас интересуют позиции, которые могут являться, к примеру, складскими ИЛИ плановыми (то есть у них может быть установлено либо одно из этих свойств, либо оба). Но при использовании двух обычных срезов отбор по свойству “Складская” = “Да” приведет к тому, что прочие строки будут отфильтрованы, даже если у них свойство «Плановая» тоже установлено срезом в значение «Да».
Стандартное решение
Множество интересных способов получить желаемый результат можно почерпнуть в статье гуру DAX Альберто Феррари и Марко Руссо («итальянцев»). Обычно примеры таких мер используют так называемые «прямые» фильтры – когда проводится сравнение с жестко заданным значением. Стандартное решение для таких мер следующее:
В итоге при поддержке Microsoft в Санкт-Петербурге 23 августа 2017 года прошла первая встреча SPb Power BI User Group (с параллельным созданием сообщества на сайте https://www.pbiusergroup.com).
Состав выступающих был весьма плотный, участвовали целых 5 спикеров:
List.Generate – одна из функций языка “M” (язык Power Query aka “Get & Transform” для Excel и редактора запросов Power BI), используемая для создания списков (lists ) по заданным правилам. В отличие от других генераторов списков (например, List.Repeat или List.Dates), правила и алгоритм генерации очередного элемента может быть практически любым, что позволяет использовать List.Generate для решения достаточно сложных задач.
Несмотря на то, что есть несколько отличных постов, описывающих использование этой функции (например, Chris Webb, Gil Raviv, PowerPivotPro, KenR), мне всегда не хватало более понятного описания – “как же это всё работает?!” или “Почему оно не работает?” и, наконец, “Что вообще имели ввиду разработчики?”
Создает список значений с четырьмя функциями, которые создают начальное значение initial , проверяют выполнение условия condition и в случае успеха выбирают результат и формируют следующее значение next . Необязательный параметр selector может также быть указан.
Скажите, вы хотели бы использовать необязательный параметр selector ? Точно? Уверены?
Можно было бы списать на несовершенство перевода, но я вас уверяю, по-английски не лучше:
Generates a list of values given four functions that generate the initial value initial , test against a condition condition , and if successful select the result and generate the next value next . An optional parameter, selector , may also be specified.
Хотя на самом деле есть еще и краткое описание функции, которое выглядит чуть более внятно:
Создает список с указанием функции начального значения, функции условия, следующей функции и необязательной функции для преобразования значений.
По крайней мере, одно очевидно: функция принимает 4 аргумента, все 4 имеют тип function:
На самом деле функция List.Generate использует достаточно простой алгоритм. В процессе генерации каждого элемента списка функция рассчитывает значение (назовем его CurrentValue), которое модифицируется и передается от одной функции-аргумента к другой в следующем цикле:
Начальное значение CurrentValue= результат вычисления функции initial .
Передать CurrentValueна вход функции condition , проверить условие и дать ответ true или false
Если результат вычисления condition равен false –закончить создание списка.
Если результат вычисления condition равен true – создать очередной элемент списка по следующему правилу:
Если параметр selector задан, то вычислить значение функции selector, получив на вход CurrentValue.
Если параметр selector отсутствует, очередной элемент создаваемого списка будет равен CurrentValue.
Вычислить значение функции next (получив на вход CurrentValue) и присвоить переменной CurrentValueновое значение – результат этого вычисления.
Перейти к шагу 2.
Как можно увидеть из этого описания, важным отличием List.Generate от других функций-итераторов языка M является то, что практически все остальные работают по принципу
For Each…Next (то есть ограничены заданным списком перебора), в то время как List.Generate использует другую логику –
Do While…Loop . Соответственно, количество элементов в созданном списке ограничивается только выполнением некоего условия.
Если записать приведенный выше алгоритм на каком-нибудь привычном (не функциональном) языке, то он мог бы выглядеть примерно так:
Visual Basic
1
2
3
4
5
6
7
8
9
10
11
12
DimNewList AsNewList
CurrentValue=initial()
DoWhilecondition(CurrentValue)
Ifselector=nullThen
NewList.Add(CurrentValue)
Else
NewList.Add(selector(CurrentValue))
EndIf
CurrentValue=next(CurrentValue)
Loop
При этом:
Функция initial не имеет аргументов и ее вычисленное значение равно значению выражения, указанного внутри нее.
Если при написании initial вы укажете, что она должна принимать какие-то аргументы, у вас все равно не будет способа подать ей на вход значения, так как ее вызов происходит где-то внутри функции List.Generate.
Если честно, то я не понимаю, почему initial вообще задается как функция, а не сразу как вычисляемое ею значение. Наверное, для этого есть причины.
Сначала всегда вычисляется результат функции initial.
Если результат первой проверки condition будет false , то список не будет создан даже при том, что initial рассчитан.
Но если результат initial пройдет первую проверку, то именно он и будет первым элементом списка. Именно поэтому initial и next обычно генерируют одинаковые по типу и структуре значения.
Функции condition , next и selector получают на вход рассчитанное значение CurrentValue, но не обязаны его использовать. Фактически, эти три функции могут не обращать внимание на CurrentValue, и использовать какую-то другую логику.
Но, если честно, не представляю себе ситуацию, когда condition (или next ) не должна использовать CurrentValue, так как это приведет либо к бесконечному циклу, либо список не будет создан.
Функции next и selector вычисляются только при условии conditon = true .
Функция selector вычисляется вне зависимости от результата функции next, рассчитанного на текущем шаге цикла.
Функция next вызывается всегда ДО создания следующего элемента списка (2-го и далее).
Например, если вы создаете список в процессе работы с каким-либо API (например, в функциях initial и next посылаете запросы на подготовку или получение отчетов), имейте ввиду следующее:
Как только List.Generate вызывается, API опрашивается как минимум 1 раз, при вычислении initial .
Количество обращений к API всегда будет как минимум на 1 больше, чем количество элементов в созданном списке (этот лишний – последний результат расчета функции next , не прошедший проверку condition )
Удобнее всего, когда initial и next возвращают тип
record . Это сильно упрощает добавление счётчиков и дополнительных аргументов для этих функций (одно из полей записи – основные данные, другое – счетчик, третье – какой-то еще параметр, используемый для генератора элементов, и так далее).
В итоге, List.Generate – это очень мощный по возможностям инструмент, хотя и немного тяжелый в освоении . Надеюсь, после этой статьи он стал понятнее и дружелюбнее. 🙂
Какое-то время назад Максим Уваров предложил мне поучаствовать в создании регулярного вебкаста о Power BI. Долго ли, коротко ли (на самом деле долго), но Максим наконец-то вернулся из Таиланда, я собрался наконец-то с мыслями, и мы в один присест записали пилотный выпуск, который пришлось разделить на три части из-за его длины (просто очень много хотелось рассказать).
Собственно, вот эти три части:
Часть 1 – говорим об изменениях в системе лицензирования Power BI, объявленных в мае 2017 года: Power BI Premium, конец халявы для Free-лицензий и так далее:
Часть 2 – первые впечатления от работы с Power Query SDK – основным подарком разработчикам от Microsoft в мае 2017 (даже не знаю, будет ли что-то такое же революционное в ближайшее время, разве что новый API внезапно появится):