Let’s say you have a few numerical columns [A], [B] and [C] in your table and want to sum them to the new column in Power Query or Query Editor in Power BI.
Three numerical columns we want to sum in the new column
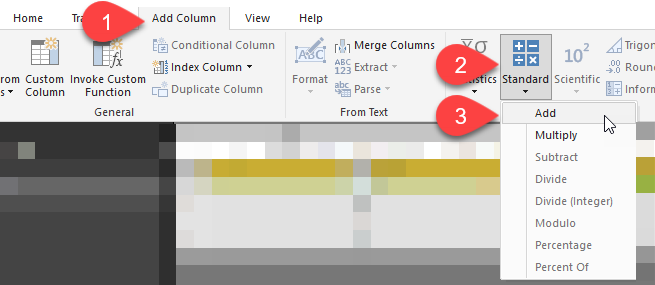
In Power Query we have special buttons for this:
Sum of columns in Power Query is easy as 1-2-3
For example, we want to sum columns [A] and [C]. Just click (holding Ctrl button) column headers you want to sum, then go to “Add Column” – “Standard” – “Add”, and you’ll get a new column named “Addition” with the row-by-row sum of desired columns:
Sum of columns [A] and [C] – sure it is
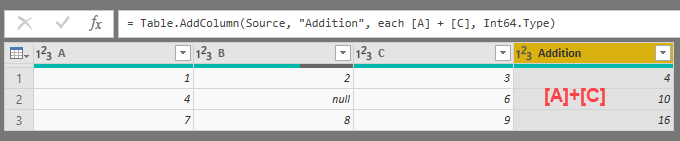
If we want to add three columns at a time, then we’ll also get a desired result:
What we’ve expected? Just simple sum of [A]+[B]+[C]
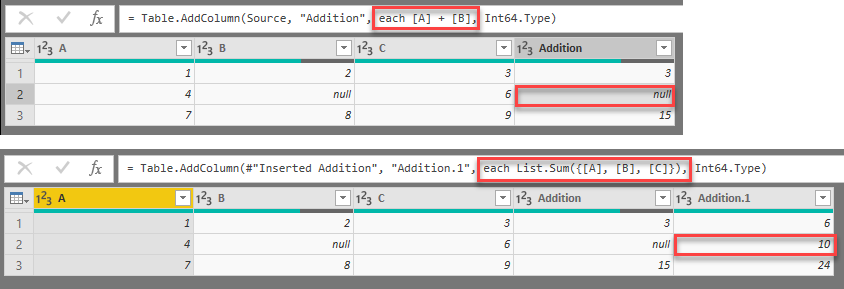
But if in this table we want so sum columns [A] and [B], we are not expecting a pitfall, aren’t we?
What could go wrong?
The reason of this behaviour is simple and it reveals itself when we look at our data a little bit close: there is a null in column [B] in that row. In Power Query formula language (M) the expression null + value always returns a null (see this excellent post of Ben Gribaudo about null type and operations with null values).
But why we get a correct result when we sum up three columns? It is because Power Query uses different formulas when we sum two columns or three and more columns:
List.Sum function used in this case ignores null values and sums up only numerical values. Indeed, it gives more intuitive result, but on the contrary has not such intuitive syntax of simple addition.
I do not know what is the reason of such difference, and already complained to the development team. But if you rely on the buttons there, then you have to be aware of such behaviour.
What is the possible solutions there? It depends on what you want to get as a result, but in any case you should take a look at the formula bar and decide what to correct there:
If the logic of your calculations assume that value + null = null, then you should use simple + symbol between column names.
If you want to get value + null = value, then you should use List.Sum finction, like in that example: List.Sum({[A], [B], [C]})
THE SAME BEHAVIOR Power Query shows when you’ll try to multiply two columns and three or more columns: with two columns there will be the simple * symbol, with three or more columns there will be List.Product function used.
Ok, it is a really short post which I planned to (and ought to) write a long time ago…
В обновлении Power BI Desktop от 22 июля 2018 появилась новая замечательная возможность – создавать связи “многие-ко-многим” (Many-To-Many, или M2M) между таблицами модели данных. Пока еще в предварительной версии, то есть не работающее в Power BI Service, но очень интересное нововведение.
До этого обновления в Power BI можно было создавать связи только двух видов: “один к одному” и “многие-к-одному“. Новый тип связи появился в связи с введением в пробную эксплуатацию так называемой “композитной”, или “составной”модели, позволяющей использовать в проекте одновременно как источники, подключенные в режиме Direct Query (например, MS SQL Server), так и источники в режиме Import (например, файл Excel), или сразу несколько источников Direct Query. Связи “многие-ко-многим” на текущий момент являются единственным способом связи между источниками, подключенными в разных режимах (DQ и Import), независимо от их фактической кратности.
Однако применение нового типа связи “многие-ко-многим” не ограничивается только рамками композитной модели – такие связи теперь можно устанавливать между любыми таблицами Power BI!
Такой тип связей открывает для разработчика новую степень свободы, если можно так выразиться. Теперь не обязательно создавать промежуточные бридж-таблицы для связывания двух таблиц по неуникальному ключу – можно настроить такую связь напрямую. Это уменьшает количество таблиц и связей между ними, делая модель проще.
Реализация связей “многие-ко-многим” в Power BI сопряжена с рядом ограничений. Сейчас их всего три (они действуют именно для таблиц, связанных таким способом):
Невозможно использовать функцию RELATED для получения данных связанной таблицы (так как связанными могут оказаться несколько строк).
Не создаются пустые строки для группировки строк, отсутствующих в связанной таблице (а также для строк, имеющих Null в столбце связи другой таблицы).
Функция ALL(), примененная к одной из таблиц, не сбрасывает фильтры, примененные к связанной таблице (а, например, в связи “один-ко-многим” функция ALL(Table) сбрасывает все фильтры со столбцов таблицы, в том числе фильтры, примененные к столбцам таблиц, связанных с находящихся на стороне “один”).
Эти ограничения не так очевидны, и неподготовленный аналитик может быть неприятно удивлён неожиданному поведению мер и визуальных элементов.
Достаточно подробно эти ограничения описаны в официальной документации, а мы с Максимом Уваровым практически сразу после выхода обновления записали видео, в котором я постарался подробно рассказать о новом типе связей, его ограничениях и подводных камнях.
Я считаю, что появление составной модели и нового вида связи между таблицами – это крупнейшее изменение в моделировании данных в Power BI после введения двунаправленной фильтрации. И хотя пока этот тип связи вызывает много вопросов, меня однозначно радует всё, что касается новых инструментов подготовки данных и моделирования в Power BI: приятно смотреть, как любимый инструмент развивается и становится всё мощнее и мощнее. А судя по опубликованному roadmap до октября 2018 года, планов относительно развития Power BI у Microsoft очень много. Нет, не так. ОЧЕНЬ МНОГО.Follow me:
Эта статья – перевод моего первого поста в этом блоге, который был опубликован 5 ноября 2015 года на английском языке. К моему удивлению, этот пост – самый популярный, за это время он набрал почти 21000 просмотров. С небольшими стилистическими правками публикую его на русском языке. В переводе помогал мой сын Дмитрий, за что ему отдельное спасибо.
Power Query – это мощный инструмент, способный на большее, чем просто брать данные из источника и переносить их в таблицу или Power Pivot. Данные можно очищать и преобразовывать множеством способов, но есть некоторые действия, привычные для Excel, которые не так удобно делать в Power Query.
Например, что, если мне нужна относительная ссылка на конкретную ячейку в таблице Power Query – значение из определённой строки в определённом столбце? Или ссылка на значение в определённом столбце на четыре строки выше? В Excel очевидно, как это сделать: нужно просто указать на нужное значение мышкой, убедиться, что из ссылки к строке убран знак “$” (знак абсолютной ссылки), и всё. Но в Power Query я не могу так просто это сделать.
Но всё же решение, хотя и непрямое, существует.
Прежде всего давайте выясним, как можно получить доступ к конкретному значению из таблицы Power Query.
Простейший способ понять адресацию в Power Query, по-моему, анализировать код шагов.
Абсолютные ссылки на строки
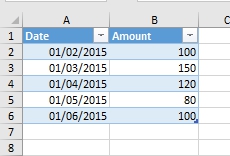
Допустим, у нас есть простая таблица из двух столбцов: даты (Date) и количества (Amount). В ней пять строк, и в первом столбце стоят, как ни странно, даты, во втором – какие-то значения:
Исходные данные
Мы хотим получить значение из ячейки B4, а именно 120. Continue Reading →Follow me:
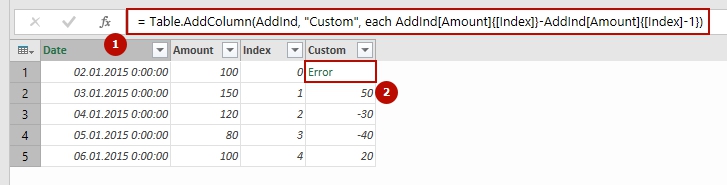
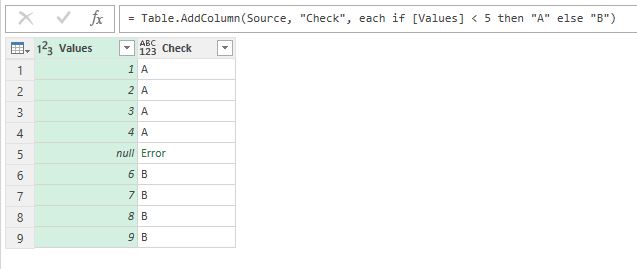
Недавно мне нужно было сделать очень простую операцию в Power Query. В столбце с числами нужно было выполнить проверку “значение меньше N” и в новом столбце вывести соответствующий текст. Функция дополнительного столбца выглядит примерно так:
1
=if[Values]<5then"A"else"B"
На самом деле некоторые значения – null (то есть пустые):
Данные содержат null и в результате сравнения возникает ошибка
И такая простая операция возвращает ошибку для этих значений!
Почему? Есть некоторая ловушка, спрятанная в глубинах документации (а именно на странице 67 PDF-файла “Power Query Formula Language Specification (October 2016)”, который можно найти тут.
Recently I needed to do the very simple thing in Power Query. I have the column of numbers and need to check if the values in this column are less than N and then put a corresponding text value in the new column. The function for the new column is something like this:
M
1
=if[Values]<5then"A"else"B"
Actually some values are not a numbers but nulls:
Data contains nulls and comparison return an error
And this simple calculation returns an error for these values!
Why? There is the catch, which is hidden in the depth of documentation (actually on the page 67 of the “Power Query Formula Language Specification (October 2016)” PDF which you can obtain there.
Иногда, особенно во время работы с таблицами-календарями, нам необходимо определить номер недели по ISO. К сожалению, “родной” функции для этого в Power Query или в Power BI нет, и для получения нужного результата приходится писать свою.
Спасибо Catherine Monier, Microsoft Excel MVP, за ссылку на готовую функцию для Power Query “Date to ISO Week”. Также по этой ссылке можно найти и обратную функцию, переводящую даты формата 2017-W02-7 в обычную дату:
Написать такую функцию не очень сложно, но приятно же, когда это уже сделали за вас? 🙂Follow me:
This is a very short post, just to make a reminder and possibly expand knowledge for me and my readers.
Sometimes, specially when working with calendar tables, we need to calculate ISO Week Number for certain date. There is no native functions in Power Query / M language / Power BI to get ISO Week number, so to obtain the desired result you need to write your own function.
Thanks to Catherine Monier, Microsoft Excel MVP, for providing the link to the “Date to ISO Week” M function already written for us. There also another function for converting ISO Week date (format input like: 2017-W02-7) to the normal date:
This function is not so hard to develop, I think, but it is always better when somebody gives you ready-to-use solution, isn’t it? 🙂Follow me:
Эта статья о работе надстройки Power Query к Excel 2010 и Excel 2013, редактора запросов Power BI и группы команд “Get & Transform” (“Получить и преобразовать”) в Excel 2016. Надеюсь, когда-нибудь эта чехарда закончится и мы сможем говорить просто Power Query.
Результатом вычисления запроса в Power Query является единственное значение. Как правило, речь идет о таблице, которую мы затем выгружаем на лист или в модель данных в Excel и Power BI. Это же требование относится также и к любым другим выражениям, вычисляемым Power Query, например, встроенным или пользовательским функциям, полям записей, записям в целом, и т.д.
Однако можно легко представить себе ситуацию, когда нам нужно, чтобы функция или запрос вместе с основным результатом вернули и другую информацию – дополнительный или промежуточный результат вычисления.
Промежуточные и дополнительные результаты запросов
Представьте, что в процессе сложных преобразований запроса Query1 последним шагом под названием
ResultTable мы получили нужный результат (таблицу), которую мы хотим загрузить в модель данных. Одним из промежуточных шагов в нашем запросе был расчет какой-то величины
ValueX , и мы хотели бы использовать ее в других выражениях или запросах:
M
1
2
3
4
5
6
7
8
9
// Query1
let
Source=…,// источник данных
…,// какие-то шаги
ValueX=…,// промежуточный результат
…,// еще какие-то шаги
ResultTable=…// получаем таблицу-результат
in
ResultTable// но она не содержит в себе данные для получения ValueX
Нам в итоге нужен и
ValueX , и, конечно же,
ResultTable .
У нас есть как минимум три способа это сделать:Continue Reading →Follow me:
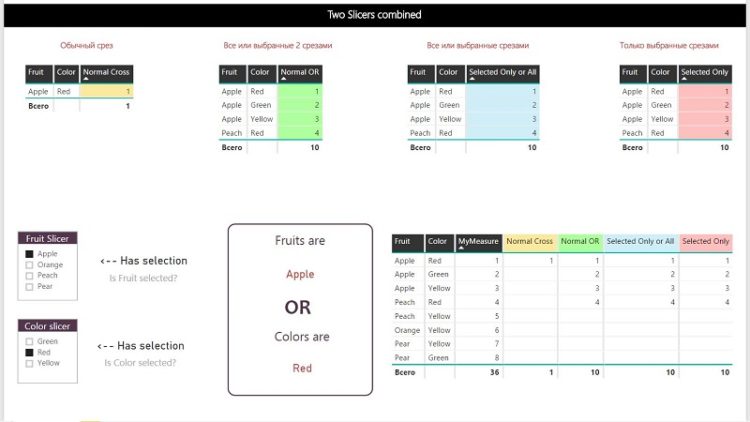
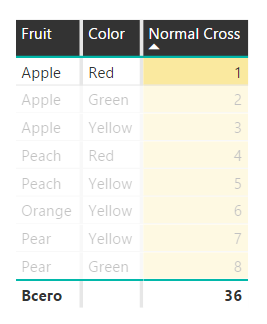
В стандартном режиме несколько срезов в Power BI работают по принципу «И», то есть пересечения примененных фильтров. Мы выбираем на одном срезе «Яблоки», на другом цвет «Красный», и получаем меры, рассчитанные только для красных яблок. Зеленые яблоки будут проигнорированы.
Обычный срез: красные яблоки
Периодически (хоть и нечасто) возникает другая задача: как заставить срезы работать по принципу «ИЛИ», то есть учитывать в мере значения обоих срезов? Например, получить одновременно все зеленые фрукты и все яблоки? Все желтое или грушевидное?
Более практичный пример: товарная позиция может быть помечена в базе как складская (за это отвечает свойство «Складская»), одновременно она помечена как плановая (за это отвечает другое свойство, «Плановая»). Для расчетов нас интересуют позиции, которые могут являться, к примеру, складскими ИЛИ плановыми (то есть у них может быть установлено либо одно из этих свойств, либо оба). Но при использовании двух обычных срезов отбор по свойству “Складская” = “Да” приведет к тому, что прочие строки будут отфильтрованы, даже если у них свойство «Плановая» тоже установлено срезом в значение «Да».
Стандартное решение
Множество интересных способов получить желаемый результат можно почерпнуть в статье гуру DAX Альберто Феррари и Марко Руссо («итальянцев»). Обычно примеры таких мер используют так называемые «прямые» фильтры – когда проводится сравнение с жестко заданным значением. Стандартное решение для таких мер следующее:
В итоге при поддержке Microsoft в Санкт-Петербурге 23 августа 2017 года прошла первая встреча SPb Power BI User Group (с параллельным созданием сообщества на сайте https://www.pbiusergroup.com).
Состав выступающих был весьма плотный, участвовали целых 5 спикеров: