Импорт данных в Power Query и Power BI из листа Excel: ловушка UsedRange
Если вы импортируете данные в Power Query или Power BI из файла Excel, обращаясь к листу целиком, будьте осторожны – вас может поджидать ловушка.
При подключении к стороннему файлу Excel нам доступны три варианта извлечения данных:
- Таблица (форматированный как таблица диапазон ячеек на листе)
- Именованный диапазон (диапазон ячеек, которому присвоено пользовательское имя)
- Лист целиком
В первом случае объект «Таблица» представляет собой уже структурированные данные с заголовками столбцов, которые впоследствии автоматически трансформируются в таблицы. Во втором случае Power Query снабдит именованный диапазон автоматическими заголовками (“Column1”, “Column2” и так далее), и дальнейшая обработка не отличается от импортированных таблиц.
Однако очень часто нужные данные не находятся в форматированной таблице или именованном диапазоне, и преобразовать их в такой вид затруднительно. Причин может быть много, например, необходимо сохранить форматирование (объединение ячеек теряется при преобразовании в таблицу), либо файлов слишком много для ручного преобразования в нужный формат.
Данные с неразмеченного листа
К счастью, Power Query может получить данные с листа целиком. Для того чтобы получить данные из неразмеченного листа, никаких особых действий предпринимать не нужно: подключаемся к файлу, находим нужный лист (в столбце [Kind] он будет иметь значение “Sheet”) и получаем данные путем обращения к его содержимому в столбце [Data]:
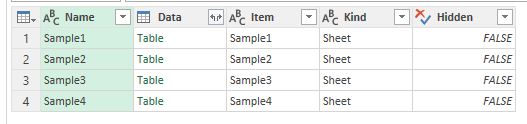
Листы Excel доступны в качестве источника наравне с таблицами и именованными диапазонами
Однако возникает вопрос, какие данные попадут в таблицу для этого листа? На листе Excel 17 179 869 184 ячеек (16 384 столбцов и 1 048 576 строк). Если бы Power Query пытался загрузить их все, это привело бы к безнадежным «тормозам» при импорте данных таким образом. Однако мы можем убедиться, что обычно количество строк и столбцов примерно соответствует заполненным.
Как же Power Query определяет нужный диапазон данных? Ответ может быть достаточно очевиден, если у вас есть достаточный опыт программирования на VBA и вы хорошо знакомы с объектной моделью Excel (и ответ вас не обрадует). А именно, Power Query использует специальный диапазон ячеек листа, который называется UsedRange.
Непредсказуемый UsedRange
Если вы не настолько хорошо знакомы с VBA и UsedRange, ниже я привел пояснение того, как работает этот объект.
Мы не видим UsedRange в списке пользовательских имен, и не можем к нему обратиться иначе, как с помощью редактора Visual Basic. Чтобы узнать его адрес на текущем листе, нажмите Alt-F11, затем Ctrl-G, и в окошке Immediate введите следующую команду:
|
1 |
?ActiveSheet.UsedRange.Address |
UsedRange – это диапазон, определенный автоматически на основе содержимого ячеек, их форматов и истории редактирования. Его левая верхняя ячейка определяется как пересечение:
- самой верхней строки, имеющей какое-то значение, формулу или формат ячейки, и
- самого левого столбца, имеющей какое-то значение, формулу или формат ячейки
Аналогично определяется правая нижняя ячейка UsedRange:
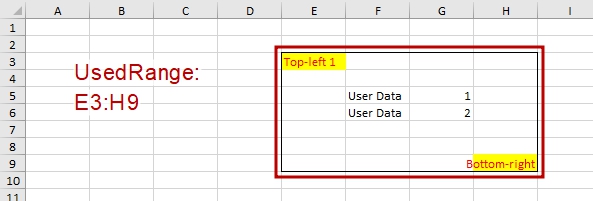
Диапазон включает в себя все использованные ячейки
При этом предсказать на основании видимых глазами деталей, какие именно ячейки Excel будет считать измененными, очень сложно, так как даже форматирование соседних ячеек и прочие неявные причины могут привести к изменению UsedRange. Например, измененная высота строки влияет на UsedRange, а измененная ширина столбца – скорее нет. Самый простой пример: если установить цвет ячейки (любой, в том числе «нет заливки»), она считается отформатированной и включается в UsedRange.
Или, например, если в ячейке задать форматирование границ толстой линией, то это, как правило, приводит к включению в UsedRange дополнительно ячейки сверху от форматированной, но расширение диапазона вниз, вправо или влево произойдет не всегда:
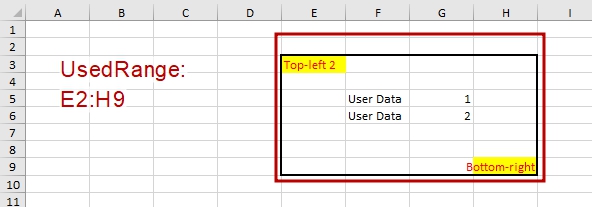
Ничего не предвещало беды, мы только изменили толщину границы
Так где ловушка?
Такое непредсказуемое поведение UsedRange при импорте с неразмеченного листа в Power Query или Power BI необходимо учитывать. Нам вряд ли помешают пустые строки и столбцы, находящиеся после данных, но пустые строки и столбцы, находящиеся перед данными – настоящая проблема, которую нельзя упускать из виду.
Некоторые пользователи любят размещать данные на листе, создавая «пробелы» между заголовками строк и столбцов и собственно таблицами. Возможно, таким образом имитируются поля документа, либо это просто удобно для восприятия. Когда речь идет об одном файле, проблемы нет. Однако если на таком шаблоне построены десятки или сотни файлов, то берегитесь, вас ждут сюрпризы.
Представьте, что у вас есть несколько (или много) файлов Excel, которые заполняют разные пользователи. Файлы имеют одинаковую структуру данных, по крайней мере, в той части, которую вы хотите извлечь. Например, искомые данные всегда находятся в диапазоне E3:H9 (4 столбца и 7 строк). Первые четыре столбца и первые две строки – пустые, не содержат значений (как на рисунках выше).
Чтобы добраться до нужного нам диапазона, мы используем подключение к папке, в которой лежат нужные нам файлы. В каждом из файлов нам нужно:
- Выбрать конкретный лист,
- Оставить только столбцы с пятого по восьмой (E:H),
- Удалить первые две строки (так как данные начинаются с третьей строки),
- Оставить первые 7 строк в получившейся таблице.
Обычно все эти шаги не вызывают больших затруднений. Мы можем написать пользовательскую функцию или воспользоваться встроенным механизмом комбинирования данных из нескольких источников (на основе примерного файла). Однако результат и в том и в другом случае может оказаться обескураживающим.
Начиная со второго шага, мы ориентируемся на структуру листа: нам нужны данные в столбцах 5-8, соответственно мы будем пытаться удалить первые 4 столбца. Однако, как мы уже увидели выше, диапазон данных, переданных в Power Query, может как включать, так и не включать пустые столбцы (в зависимости от того, были ли изменены ячейки в нем).
Соответственно, если Power Query загрузит лист начиная со столбца A, то нужно удалять четыре первых столбца – они пустые и лишние. Если же в первых 4 столбцах листа нет данных или форматирования (то есть они не попали в UsedRange), они не загрузятся в Power Query. Первым загруженным окажется пятый столбец E, с которого начинается нужный диапазон данных. Но тогда четыре первых столбца нельзя удалять!
То же самое касается и строк: даже если первые две строки не содержат значений, они могут быть загружены или не загружены в зависимости от того, включает ли их в себя UsedRange. Всегда удаляя первые две строки в редакторе запросов, мы рискуем случайно удалить и нужные нам данные. В результате дальнейшая обработка может привести к ошибкам или стать просто невозможной.
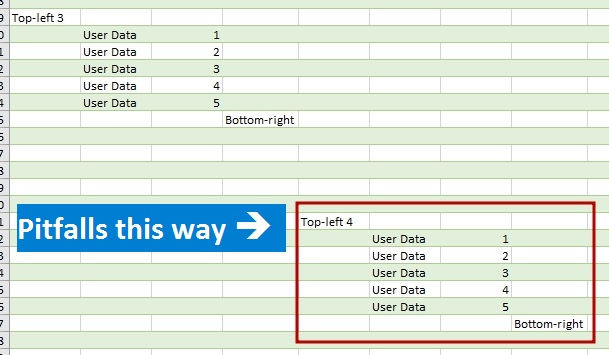
Аналогичная ситуация – при импорте данных из нескольких листов одного файла. Я подготовил файл (скачать по ссылке можно здесь), в котором на 4 листах расположены одинаковые блоки данных в диапазоне “E3:H9” (как в примере выше). При этом на каждом из листов UsedRange разный (адреса этих диапазонов можно увидеть, запустив кнопкой небольшой макрос):
- Sample1: E3:H9
- Sample2: E2:H9
- Sample3: E1:J12
- Sample4: A1:J13
Как видите, на листе Sample4 импортируемый диапазон начинается в ячейке А1 – это четыре лишних пустых столбца. Если при разворачивании столбца [Data] мы оставим только 4 первых столбца (как нам предложит Power Query по умолчанию), данные с листа Sample4 полностью потеряются:
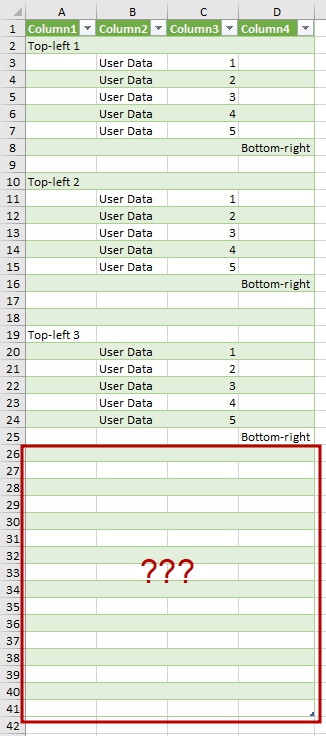
Куда делись данные с четвертого листа?
Если попросить Power Query загрузить все заголовки столбцов и развернуть таблицы полностью, то мы увидим, куда исчезли наши данные:
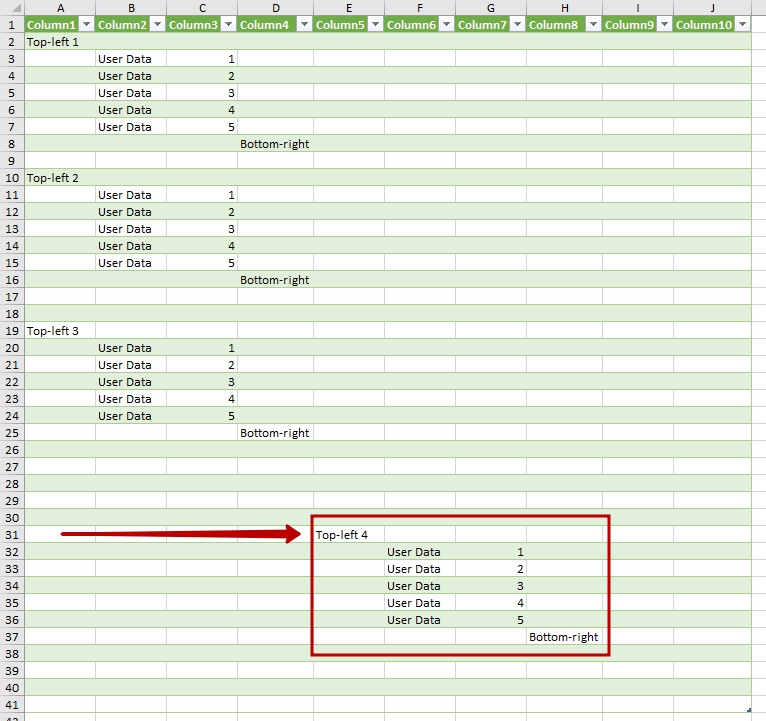
Данные совсем не там, где ожидалось их увидеть!
Можно заметить, что последний блок не только «уехал» вправо, но и расстояние между блоками непредсказуемо. Ну и как теперь объяснить Power Query, что диапазон, имеющий точную позицию на листе, может оказаться где угодно?
Резюме
Теперь вы можете представить глубину проблемы. Хорошо, если у нас есть какие-то признаки, по которым мы можем опознать левую верхнюю ячейку нужного диапазона. Однако если ее значение не фиксировано и может быть любым (например, изменяющаяся дата или имя менеджера), задача в рамках Power Query становится почти невыполнимой.
В любом случае, решить ее средствами Power Query на данный момент очень сложно. Даже если написать функцию, проверяющую первые столбцы/строки на пустоты и удаляющие их, пока не наткнемся на заполненную строку, мы не избавлены от ситуации, когда ненужные нам строки или столбцы на самом деле не пустые и содержат какие-то значения: тогда мы не сможем удалить строки/столбцы по признаку пустоты. Каким-то способом заставить Power Query получать данные, начиная с ячейки А1, на данный момент невозможно.
Если у вас есть возможность разметить данные на листе как таблицу или именованный диапазон, обязательно делайте это, не полагайтесь на импорт данных с листа.
Относительно практичный способ для предварительной обработки неразмеченных листов – вручную или посредством макроса присвоение имен нужным диапазонам. Это может быть сделано несколькими строками кода VBA, но подходит уже не для всех, и далеко не всегда возможно (что если нужный файл недоступен для редактирования?).
Еще одним трюком может стать обязательное размещение в ячейке А1 хоть какой-то информации или формата: можно написать маленький макрос, проверяющий адрес UsedRange и при необходимости маркирующий ячейку А1 как «использованную». Но это тоже «костыль», которому не место в таком серьезном инструменте, как Power Query или Power BI.
Я считаю использование UsedRange для определения диапазона импорта ошибочным решением. Power Query не различает форматы ячеек, и смысла в UsedRange никакого нет.
По моему мнению, необходимо, чтобы Power Query при импорте с неразмеченного листа брал данные начиная с ячейки А1 и до пересечения последней строки и последнего столбца, содержащих какие-либо значения. В таком случае мы можем гарантировано ориентироваться на начало блока, содержащего данные, и не будем брать лишние (пустые) столбцы и строки, идущие после последних заполненных ячеек. В крайнем случае, такой вариант импорта может быть опциональным, но это будет в любом случае лучше, чем сейчас.
PS. Если вы хотите поднять свои знания о Power Query для Excel и Power BI, и научиться применять этот инструмент правильно, очень рекомендую следующие книги:
Share this: