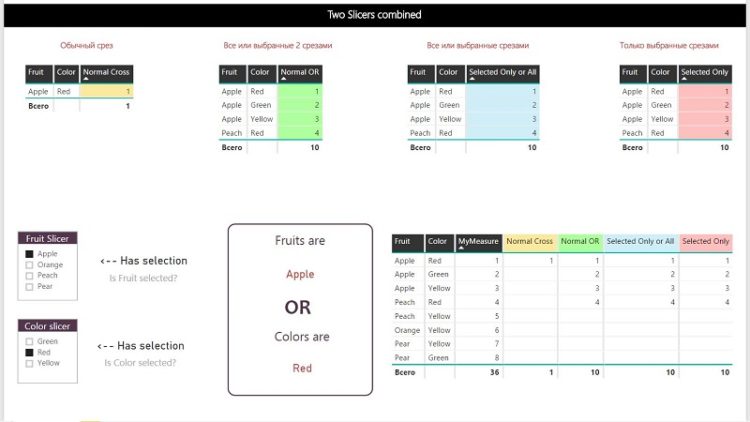
Объединяем выбор на разных срезах в DAX: Динамический фильтр “ИЛИ”
В стандартном режиме несколько срезов в Power BI работают по принципу «И», то есть пересечения примененных фильтров. Мы выбираем на одном срезе «Яблоки», на другом цвет «Красный», и получаем меры, рассчитанные только для красных яблок. Зеленые яблоки будут проигнорированы.
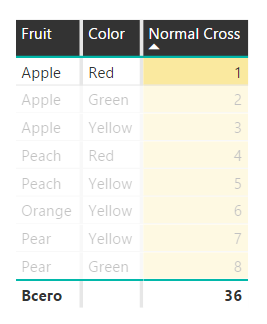
Обычный срез: красные яблоки
Периодически (хоть и нечасто) возникает другая задача: как заставить срезы работать по принципу «ИЛИ», то есть учитывать в мере значения обоих срезов? Например, получить одновременно все зеленые фрукты и все яблоки? Все желтое или грушевидное?
Более практичный пример: товарная позиция может быть помечена в базе как складская (за это отвечает свойство «Складская»), одновременно она помечена как плановая (за это отвечает другое свойство, «Плановая»). Для расчетов нас интересуют позиции, которые могут являться, к примеру, складскими ИЛИ плановыми (то есть у них может быть установлено либо одно из этих свойств, либо оба). Но при использовании двух обычных срезов отбор по свойству “Складская” = “Да” приведет к тому, что прочие строки будут отфильтрованы, даже если у них свойство «Плановая» тоже установлено срезом в значение «Да».
Стандартное решение
Множество интересных способов получить желаемый результат можно почерпнуть в статье гуру DAX Альберто Феррари и Марко Руссо («итальянцев»). Обычно примеры таких мер используют так называемые «прямые» фильтры – когда проводится сравнение с жестко заданным значением. Стандартное решение для таких мер следующее:
|
1 2 3 4 5 6 7 8 |
= CALCULATE ( [MyMeasure]; FILTER ( 'Table1'; 'Table1'[Color] = "Red" || 'Table1'[Fruit] = "Apple" ) ) |
или
|
1 2 3 4 5 6 7 8 9 10 |
= CALCULATE ( [MyMeasure]; FILTER ( 'Table1'; OR ( 'Table1'[Color] = "Red"; 'Table1'[Fruit] = "Apple" ) ) ) |
Динамическое объединение срезов
Наша задача сложнее: нам нужно сделать так, чтобы значения для сравнения не задавались жестко в формуле, а выбирались срезами, а также учитывался множественный выбор на срезе (например, не только “Яблоки”, но и список {“Яблоки”, “Груши”, “Апельсины”}).
Мы будем использовать для примеров простой набор данных ‘Table1’:
| Value | Color | Fruit |
| 1 | Red | Apple |
| 2 | Green | Apple |
| 3 | Yellow | Apple |
| 4 | Red | Peach |
| 5 | Yellow | Peach |
| 6 | Yellow | Orange |
| 7 | Yellow | Pear |
| 8 | Green | Pear |
Для реализации идеи нам понадобятся несвязанные, или «отсоединенные» срезы – маленькие таблички из одного столбца, содержащие уникальные значения для срезов по столбцам “Color” и “Fruit”.
Эти таблички не должны иметь активных связей в модели данных с основной таблицей, так как при их наличии будет происходить автоматическая фильтрация срезом подчиненной (находящейся на стороне связи «много») таблицы, и придется прилагать дополнительные усилия по сбрасыванию этих фильтров. Это нам совсем не нужно.
Такие таблицы (справочники для срезов) очень быстро создаются из основных таблиц при помощи Power Query или при помощи вычисляемых таблиц DAX – нам нужно, сославшись на таблицу-источник, выбрать нужный столбец и оставить в нем только уникальные значения.
|
1 |
ColorsSlicer = DISTINCT('Table1'[Color]) |
|
1 |
FruitsSlicer = DISTINCT(‘Table1’[Fruit]) |
После создания таких таблиц необходимо убедиться, что не были созданы автоматические активные связи. Если Power BI или Power Pivot создали активные связи за вас, их нужно сделать неактивными (деактивировать).

Мера, которую мы будем подвергать воздействию срезов, будет очень простая, но на самом деле может быть абсолютно любой:
|
1 |
MyMeasure = SUM ( Table1[Value] ) |
Итак, если пользователь выберет какие-то значения на двух срезах, то мера должна получить для расчета данные, удовлетворяющие либо одному, либо другому срезу.
Осталось определить, какое поведение меры мы хотим увидеть, если пользователь ничего не выбрал на обоих срезах или сделал выбор только на одном срезе:
| Вариант поведения | Ничего не выбрано | Выбор на 1 срезе | Выбор на 2 срезах |
| Вариант 1. Всё или объединение | Показываем всё | Показываем всё | Объединение срезов |
| Вариант 2. Всё или выбранное | Показываем всё | Только значения для 1 среза | |
| Вариант 3. Ничего или выбранное | Ничего | Только значения для 1 среза |
Вариант 1. Всё или объединение
Фактически мера для этого варианта учитывает привычное поведение среза: если на нём ничего не выбрано, то в расчет принимаются все значения. Если выбор сделан только на одном срезе, то для второго среза берутся все значения. Это значит, что при объединении мы опять получим полный набор данных. Но если фильтр сделан на обоих срезах, то эта мера даст нам нужное объединение.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Normal OR (relations) = CALCULATE ( [MyMeasure]; UNION ( CALCULATETABLE ( 'Table1'; USERELATIONSHIP ( 'Table1'[Fruit]; 'FruitsSlicer'[Fruit] ) ); CALCULATETABLE ( 'Table1'; USERELATIONSHIP ( 'Table1'[Color]; 'ColorsSlicer'[Color] ) ) ) ) |
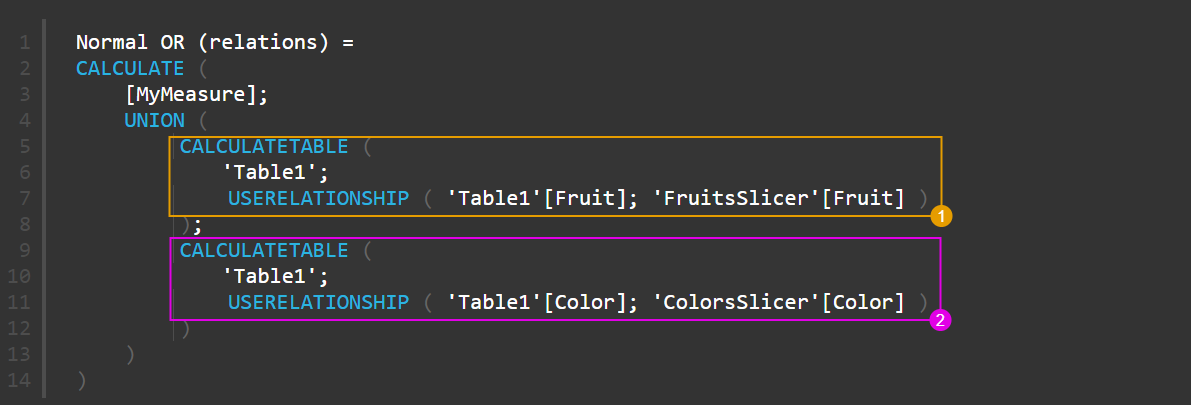
Объединяем выбор на срезах при помощи неактивных связей
Эта мера учитывает неактивные связи в нашей модели данных (их, понятное дело, нужно создать):
- сначала мы включаем связь между таблицей среза по фруктам и основной таблицей, и получаем отфильтрованные строки основной таблицы (строки 5-7).
- Затем мы включаем связь между таблицей среза по цвету и основной таблицей, и получаем отфильтрованные строки основной таблицы (строки 9-11).
Эти две операции работают независимо друг от друга, поэтому включение связи в одной части формулы не влияет на включение связи в другой части.
- Объединяем полученные таблицы (за это отвечает функция UNION в строке 4). Результат объединения будет фильтровать нашу таблицу данных.
Физические связи дают нам преимущества в скорости (они отрабатываются быстрее любой формулы), однако в нашем случае использование UNION имеет также и небольшой недостаток. Функция UNION не удаляет дубликаты, то есть в объединенной фильтрующей таблице одна и та же строка может оказаться дважды (один раз при отборе для цвета, один раз при отборе для фруктов). В принципе, можно поместить конструкцию UNION внутрь функции DISTINCT, но я уверен, что никакого заметного улучшения мы не увидим.
Можно и дальше усовершенствовать эту схему с применением неактивных связей, но я хочу показать также и другие варианты решения задачи.
Следующая мера подразумевает, что наши таблицы для срезов не имеют активных связей с основной таблицей (или имеют неактивные, которые мы не будем использовать):
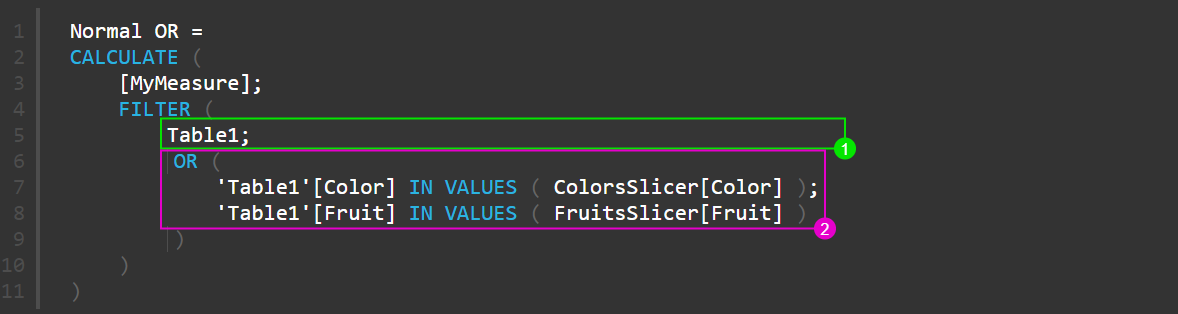
Объединяем выбор на срезах с использованием функции FILTER
В этой мере мы используем традиционную функцию FILTER. Так как FILTER – это итератор, то он проверяет все строки своего первого аргумента (табличного выражения) на соответствие условиям.
В условиях проверки мы используем достаточно новый для DAX оператор IN. Фактически этот оператор – это shortcode для функции CONTAINSROW, но он гораздо нагляднее и интуитивно понятнее, особенно если вы имеете опыт в SQL: слева – проверяемое значение, справа – список, в котором мы ищем значение. В качестве списка мы передаем отобранные срезом значения цвета (или фруктов, соответственно).
В этом случае мы берем всю таблицу Table1 (строка 5), и проверяем каждую строку:
- попадает ли в этой строке значение столбца [Color] в список отобранных значений среза по цветам (строка 7),
ИЛИ
- попадает ли в этой строке значение столбца [Fruit] в список отобранных значений среза по фруктам (строка 8).
Что, собственно, мы и хотели узнать.
Однако использование в качестве табличного аргумента FILTER таблицы данных целиком – не самая лучшая идея. Когда таблица небольшая, мы можем и не заметить разницы, но если наша таблица достаточно велика, и связана со многими справочниками, то «дергать» ее по мелочам не стоит.
В следующем варианте (вместо Table1 целиком) мы будем использовать функцию CROSSJOIN, чтобы создать таблицу из всех возможных сочетаний цветов и фруктов, имеющихся в контексте вычислений:
|
1 2 3 4 5 6 7 8 9 10 11 |
Normal OR = CALCULATE ( [MyMeasure]; FILTER ( CROSSJOIN ( VALUES ( Table1[Color] ); VALUES ( Table1[Fruit] ) ); OR ( 'Table1'[Color] IN VALUES ( ColorsSlicer[Color] ); 'Table1'[Fruit] IN VALUES ( FruitsSlicer[Fruit] ) ) ) ) |
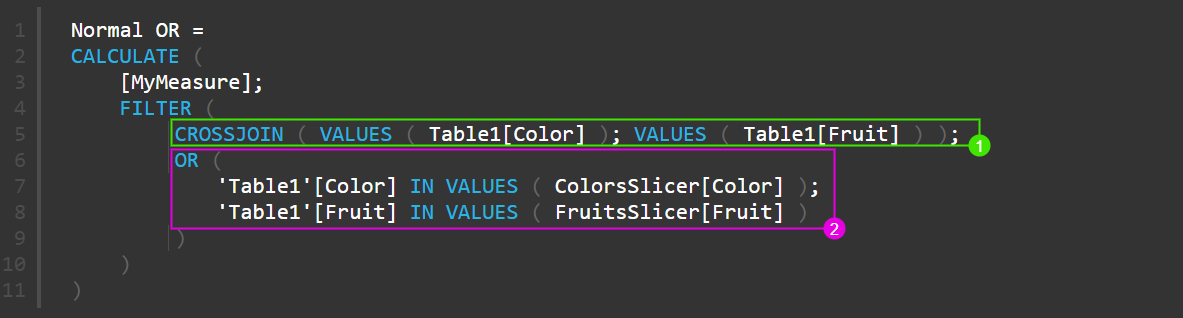
FILTER + CROSSJOIN
Обратите внимание, что условие проверки осталось тем же (строки 6-8). Разница с предыдущей мерой в том, что таблица, которую мы перебираем построчно для создания фильтра, теперь содержит картезианское произведение цветов и фруктов. Например, если в наших данных всего 3 цвета и 4 фрукта (как в моем примере), то таблица, которая будет проверяться, будет содержать 3*4 = 12 строк. Сколько же строк попадает в перебор при проверке Table1 целиком – зависит, конечно, от ваших данных, но есть серьезное подозрение, что их там может быть гораздо больше.
Ну и последнее усовершенствование, которое есть смысл сделать для этой меры, это вынести списки значений срезов в переменные:
|
1 2 3 4 5 6 7 8 9 10 11 |
Normal OR = VAR Colors = VALUES ( ColorsSlicer[Color] ) VAR Fruits = VALUES ( FruitsSlicer[Fruit] ) RETURN CALCULATE ( [MyMeasure]; FILTER ( CROSSJOIN ( VALUES ( Table1[Color] ); VALUES ( Table1[Fruit] ) ); OR ( 'Table1'[Color] IN Colors; 'Table1'[Fruit] IN Fruits ) ) ) |

Используем переменные (VAR) для сохранения результатов выбора на срезах
Таким образом, списки значений срезов будут посчитаны один раз, перед расчетом меры, а не будут рассчитываться для каждой проверяемой строки. Мелочь, а приятно.
Вариант 2. Всё или выбранное
Этот вариант меры подразумевает следующее поведение:
- Если пользователь не сделал выбора ни на одном срезе, то мера считает так, будто все значения выбраны.
- Если же пользователь сделал выбор на только на одном из срезов, то мера должна применить его как обычный срез (второй срез не работает).
- Если пользователь сделал выбор на двух срезах, то мера должна применить объединение фильтров из двух срезов, как и задумано.
Нам понадобятся дополнительные проверки – сделан ли хоть какой-то выбор на срезе.
Добавим в предыдущую меру еще две переменные:
|
1 2 |
VAR ColorsFiltered = ISCROSSFILTERED ( ColorsSlicer ) VAR FruitsFiltered = ISCROSSFILTERED ( FruitsSlicer ) |
Эти переменные имеют значение TRUE, если на соответствующем срезе сделан выбор (то есть отмечен хоть один элемент).
Затем нам нужно немного модифицировать проверку сочетаний цвета и фруктов, в следующей логике:
- Не сделан выбор на срезе Colors И не сделан выбор на срезе Fruits,
(эта проверка говорит нам, что если выбор не сделан, то никакие фильтры не применяем)
ИЛИ применимо любое из условий:
- На срезе Colors сделан выбор, И значение Table1[Color] содержится в списке выбранного на срезе
- На срезе Fruits сделан выбор, И значение Table1[Fruit] содержится в списке выбранного на срезе
(эта проверка говорит нам, что мера будет посчитана только для тех фильтров, которые напрямую задаются срезами)
Получается чуть более громоздкая внешне, но в целом простая мера:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Selected Only or All = VAR ColorsFiltered = ISCROSSFILTERED ( ColorsSlicer ) VAR FruitsFiltered = ISCROSSFILTERED ( FruitsSlicer ) VAR Colors = VALUES ( ColorsSlicer[Color] ) VAR Fruits = VALUES ( FruitsSlicer[Fruit] ) RETURN CALCULATE ( [MyMeasure], FILTER ( CROSSJOIN ( VALUES ( Table1[Color] ), VALUES ( Table1[Fruit] ) ), OR ( AND ( NOT ColorsFiltered, NOT FruitsFiltered), OR ( AND ( ColorsFiltered, 'Table1'[Color] IN Colors ), AND ( FruitsFiltered, 'Table1'[Fruit] IN Fruits ) ) ) ) ) |
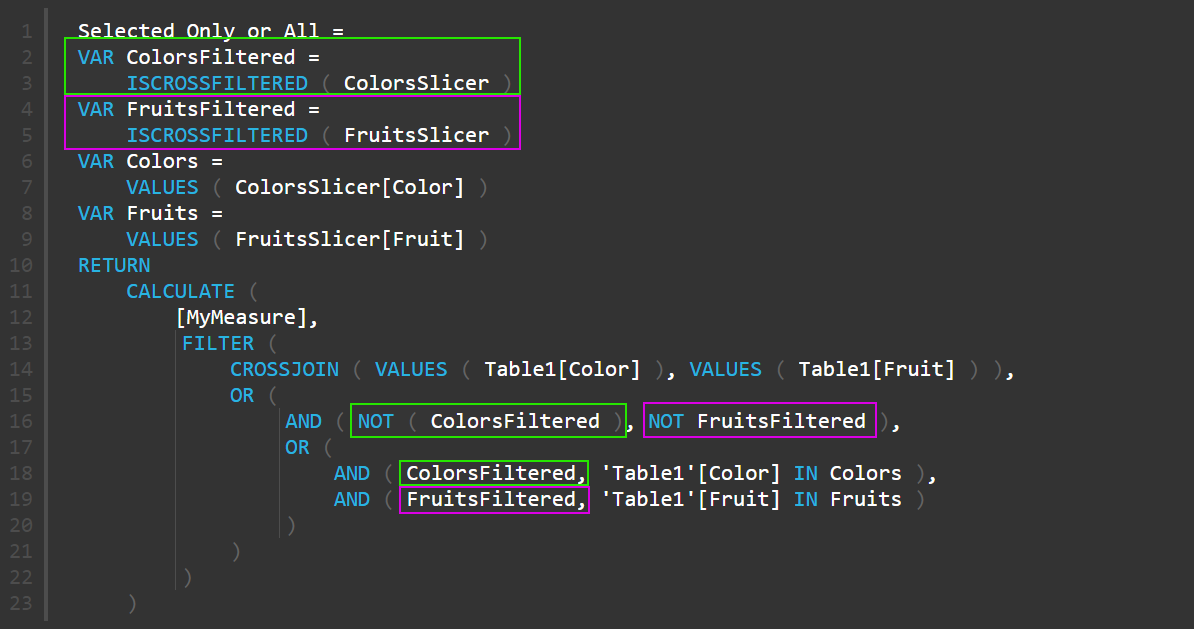
Мера для варианта 2 – либо всё, либо только отобранное срезами
Вариант 3. Ничего или выбранное
Этот вариант проще предыдущего и подразумевает следующий сценарий:
- Если пользователь ничего не выбрал на срезах, то ничего и не считаем.
- Если же пользователь сделал выбор на только на одном из срезов, то мера должна применить его как обычный срез (второй срез не работает).
- Если пользователь сделал выбор на двух срезах, то мера должна применить объединение фильтров из двух срезов, как и задумано.
Как видите, отличие от предыдущей меры только в первом пункте: если не выбрано ничего, предыдущая мера считает все значения, а эта буквально требует сделать хоть какой-то выбор.
Чтобы реализовать такой подсчет, нам достаточно просто убрать из предыдущей меры проверку соответствующего условия (что никакой выбор не сделан). Теперь будет работать только такая проверка:
- На срезе Colors сделан выбор, И значение Table1[Color] содержится в списке выбранного на срезе
ИЛИ
- На срезе Fruits сделан выбор, И значение Table1[Fruit] содержится в списке выбранного на срезе
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Selected Only = VAR ColorsFiltered = ISCROSSFILTERED ( ColorsSlicer ) VAR FruitsFiltered = ISCROSSFILTERED ( FruitsSlicer ) VAR Colors = VALUES ( ColorsSlicer[Color] ) VAR Fruits = VALUES ( FruitsSlicer[Fruit] ) RETURN CALCULATE ( [MyMeasure]; FILTER ( CROSSJOIN ( VALUES ( Table1[Color] ); VALUES ( Table1[Fruit] ) ); OR ( AND ( ColorsFiltered; 'Table1'[Color] IN Colors ); AND ( FruitsFiltered; 'Table1'[Fruit] IN Fruits ) ) ) ) |
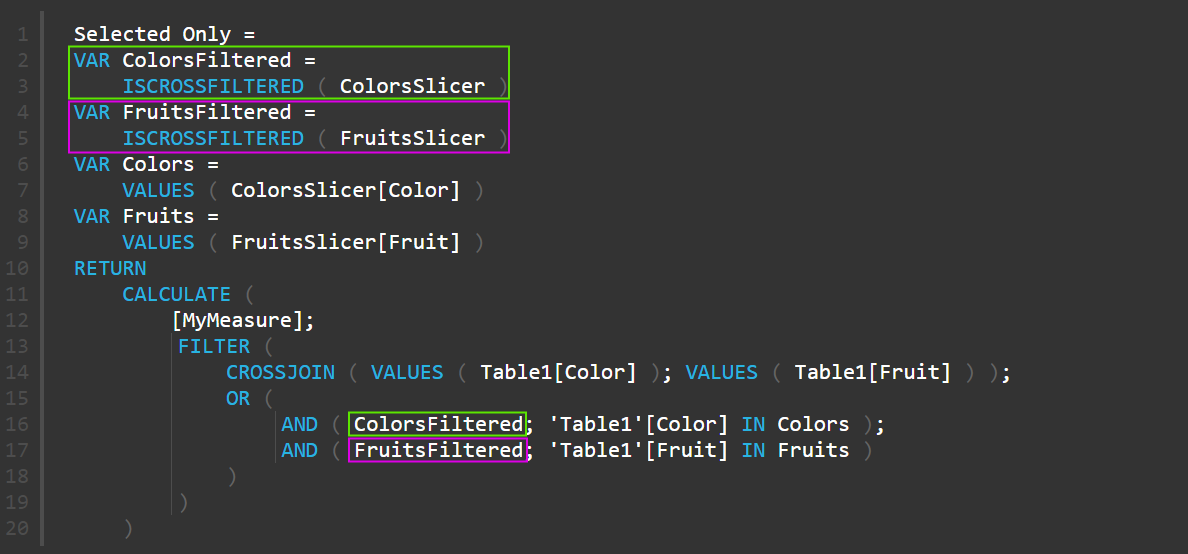
Мера для варианта 3: Либо явно выбранное на срезе, либо ничего
Резюме
Цель этой статьи – не продемонстрировать совершенные формулы или идеальные практики, а показать, что даже такие нетривиальные задачи, как объединение (комбинирование, и т.п.) значений срезов могут быть решены вполне понятными и несложными инструментами DAX. Уверен, что показанные в этой статье приемы могут быть полезны и для решения других практических задач.
Также я безусловно уверен, что эти формулы не идеальны. Если бы я был преподавателем или тренером, я сам попросил бы вас создать меры с использованием USERELATIONSHIP для второго («всё или выбранное») и третьего («ничего или выбранное») случаев (мне было лень их писать). Но, если захотите предложить и другие, более экономные варианты, буду очень рад.
Для демонстрации этих мер и того, как они работают, я сделал небольшой PBIX-файл. Скачать его можно тут.
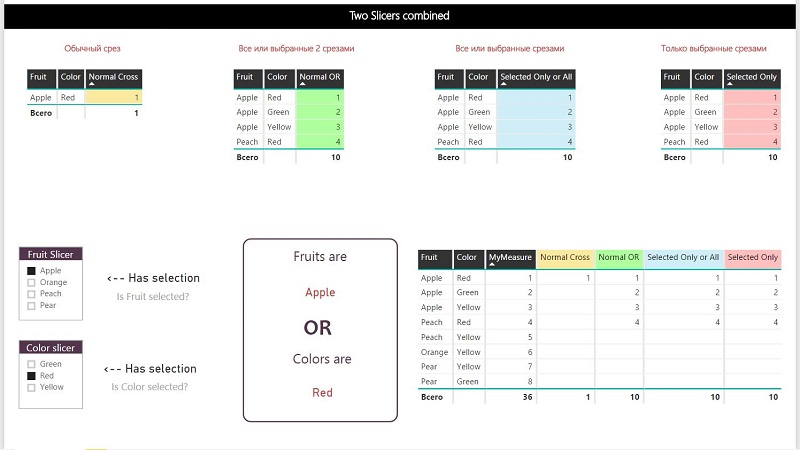
В файле можно посмотреть, как работают срезы ИЛИ
P.S.
Как обычно у меня бывает, вместо коротенького рассказа получился нормальный такой лонгрид.
К тому же просто дать меру и не рассказать, как она работает, конечно, можно… но очень скучно. Ни вам skill не прокачать, ни мне удовольствия 🙂
Share this: