Incremental Refresh For Pro Accounts With Power BI Service Dataflows
Incremental refresh is a high-demand option in Power BI. Microsoft already provided it for the Premium capacities, but for the Pro accounts it is still in waiting list.
However, with introduction of dataflows in Power BI Service, an incremental refresh implementation becomes available for Pro accounts too.
I won’t to describe dataflows in detail here since there is a lot of blogs and resources about it (but I’ll provide a few links in the bottom of the post).
Concept
All you need to know now on how to implement an incremental refresh, is that
- Dataflow in Power BI Service is a set of web-based Power Query queries (named as ‘entities’).
- Each dataflow could be refreshed manually or by the its own schedule.
- The result of evaluation of a dataflow’s entities then stored in Azure Data Lake Storage Gen2 as tables (more precisely as CSV files).
- Then you can use dataflows (their entities) as a data sources in your Power BI dataset.
Let’s start from this point.
What is the incremental refresh at all? In simple words, it means that in the single data import action we are refreshing (updating) only the part of data instead of loading all the data again and again. In the other words, we are dividing data in two parts (partitions): first part does not need refresh and should remain untouched, second part must be refreshed to bring in updates and corrections.
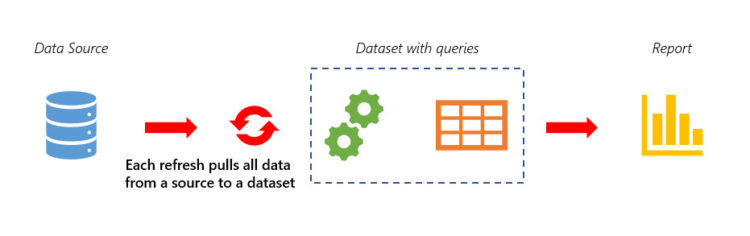
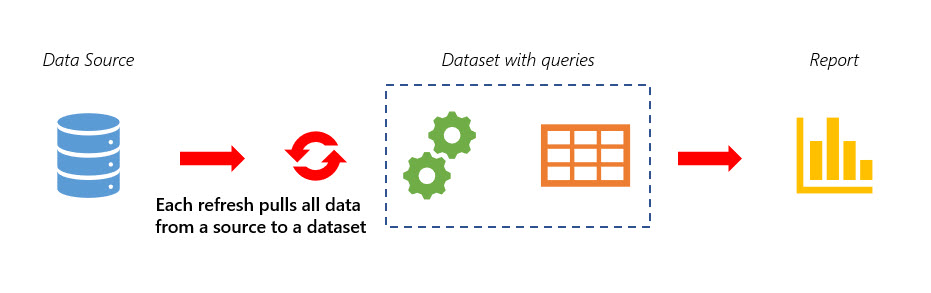
In the Power BI paradigm without dataflows we are connecting a dataset to a data source directly. Dataset contains queries which pull data from the source and so on. If we are working with some load-sensitive or slow data sources, like Web-API or oData, we must load all needed data from this source again and again, possibly reaching the limits and increasing refresh time.
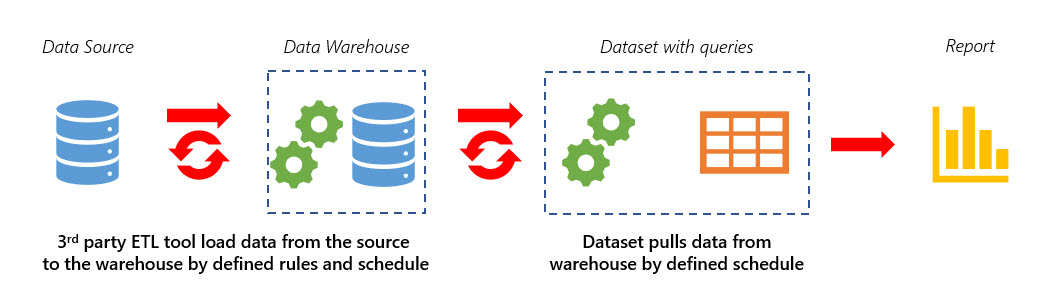
So, the best practice for such sources is a “warehouse-in-the-middle”: we should use some ETL tool to extract data from the source, load it to a warehouse and then use that warehouse as a source for a Power BI dataset. ETL tool which we’ll use for this schema should load to a warehouse only new parts of data, performing an incremental refresh.
Incremental Refresh Realization
With introduction of the dataflows in Power BI Service we do not need a separate 3rd-party ETL tool and a separate warehouse.
All we need is to create two (or more, depending on your incremental refresh logic) dataflows with a different refresh schedule.
Imagine we have a ‘Sales’ table in the data source. This table contains orders data since 01/01/2015 up to today.
We need all this data in our Power BI dataset, but, with the direct connection of dataset to the source, all the ‘Sales’ table will be transferred from the source to the dataset when we are refreshing it.
Instead of this, we create a dataflow and an entity in it, which will load the data for all the years before the current year/quarter/month (i.e. data which won’t change, depending on the business rules in your company). Refresh this dataflow only once at the creation stage and then just don’t set any refresh schedule for it. The result of this entity evaluation then stored in ADLSg2. Lets name in as ‘Entity1’.
Then create a new dataflow with an entity which will load only the data needed to refresh (for example, by the date since the end period of the ‘Entity1’ up to yesterday). Lets name it as ‘Entity2’. The result of this entity evaluation also stored in ADLSg2. For this dataflow you can set, for example, a daily refresh.
That’s all. We’ve got two partitions, one with refreshing set off, one with the scheduled refresh. Then we can connect a dataset to these entities (not to the data source) when authoring a report. When we’ll refresh a dataset, it will take already stored in ADLSg2 historical data from one entity and refreshed recent data from other. The data source will be queried only for the recent data by the ‘Entity2’ scheduled refresh, but the historical data will be loaded to the dataset only from the ADLSg2, do not touching data source.
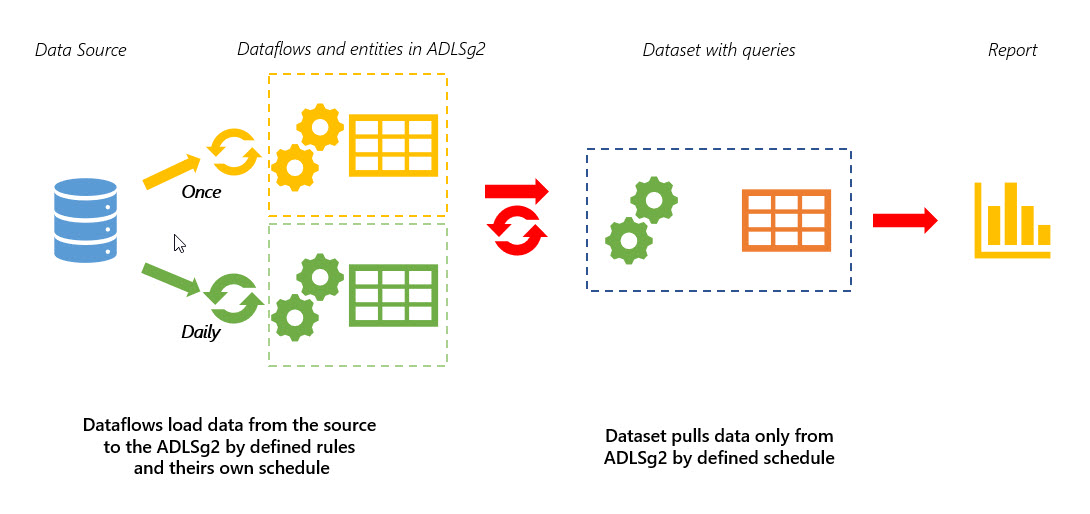
You can see, we can implement different logics with this method, and not only for the one table. You can arrange entities which load a historical data in a one dataflow, monthly updated in a second, daily updated in a third and so on.
Of course, this approach cannot replace built-in incremental refresh, but it is very flexible and allows to create refresh logics not only by date, but by other significant fields also.
Need to know more about dataflows?
What to read about the dataflows:
- Microsoft documentation on dataflows
- Power BI dataflows whitepaper
- Matthew Roche’s blog
- Reza Rad blog
- REST API for dataflows in Power BI
Share this: