Faster Than Joins! Power Query Record as Dictionary: Part 3
Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →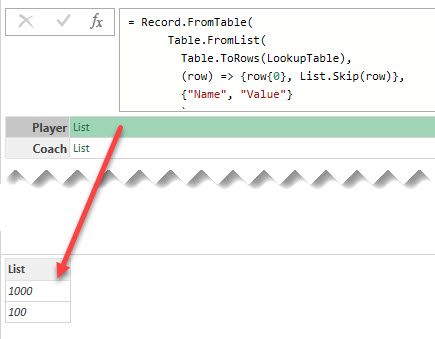
Using the Record.FieldOrDefault function in Power Query to lookup values from dictionary record and handle missing keys
Continue Reading →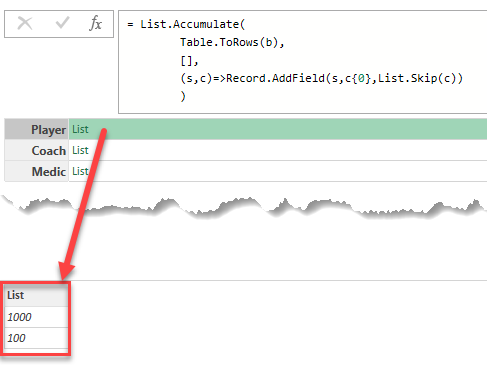
How to use a special dictionary record for a performant lookup for values in Power Query
Continue Reading →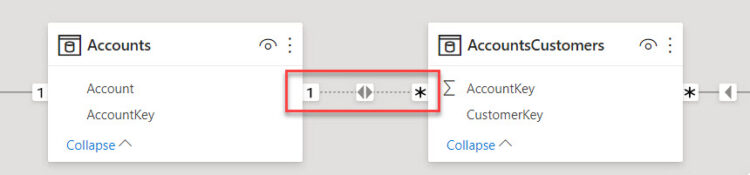
Двунаправленные связи в модели данных Power BI и Analysis Services позволяют эффективно решать некоторые проблемы анализа, но могут приводить к неоднозначности – ситуации, когда между таблицами существует более одного пути фильтрации. В таком случае движок DAX пытается при помощи сложного алгоритма выбрать наиболее подходящий путь, и результаты могут оказаться весьма неожиданными для разработчика.
Знание некоторых особенностей работы алгоритма позволяет получать предсказуемые результаты при помощи функций управления связями USERELATIONSHIP и CROSSFILTER.
В этой статье рассмотрю сразу два аспекта работы алгоритма, описание которых не встречалось мне ранее:
В первые несколько лет после запуска Power BI двунаправленные связи создавались в модели данных по умолчанию. Наверное, кто-то в Microsoft решил, что такая фишка будет очень удобна начинающим пользователям, создающим простые модели-звездочки с минимумом таблиц и связей между ними. Но, в конце концов, это стало приводить к нарастающему валу вопросов о «странных» результатах вычислений, и от двунаправленных связей «по умолчанию» было решено отказаться, ко всеобщему благу.
Лучше всего сложности, связанные с двунаправленными связями, описаны в статьях Альберто Феррари и Марко Руссо на сайте sqlbi.com, а также в их книге «Подробное руководство по DAX». Например, вот такая статья «Bidirectional relationships and ambiguity in DAX» и сопутствующее ей видео прекрасно показывают суть проблемы (рекомендую ее прочесть, хотя бы при помощи онлайн-переводчика, перед тем, как двигаться дальше).
Попробую вкратце сформулировать эту проблему так:
В своей статье Феррари пишет, что алгоритм, который внутри движка DAX решает проблемы неоднозначности, слишком сложный, чтобы его можно было объяснить «на пальцах». Это действительно так, и мне пришлось недавно столкнуться с этим в рабочем проекте. Это «столкновение» подвигло меня на некоторые исследования, которые привели к удивительным выводам.
Для иллюстрации проблемы я сначала возьму один из демонстрационных файлов к главе 15 книги «Подробное руководство по DAX». В этом файле представлена супер-упрощенная модель данных, иллюстрирующая следующую бизнес-проблему:
'Transactions'.'Customers') может управлять несколькими счетами (таблица 'Accounts'), и у одного счёта может быть несколько владельцев.'AccountsCustomers', которая содержит в себе пары значений AccountKey – CustomerKey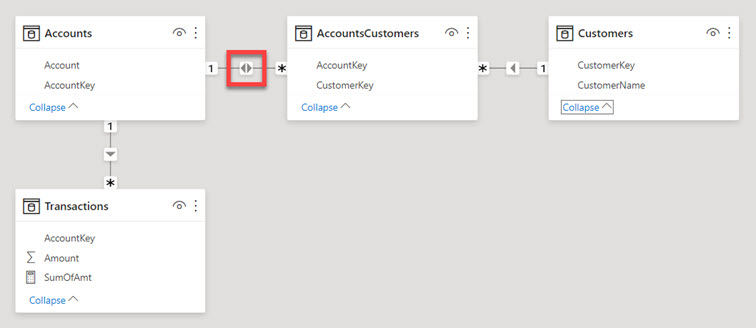
Чтобы мы могли в такой модели ответить на вопрос: «Какой оборот по счетам каждого клиента?», мы должны сделать двунаправленной связь между таблицей-мостом 'AccountsCustomers' и таблицей 'Accounts', таким образом, чтобы фильтр от таблицы 'Customers' мог добраться до таблицы 'Transactions'.
Мы можем включить двустороннюю фильтрацию двумя способами:
'AccountsCustomers' и 'Accounts' на двунаправленное в свойствах связи в модели (как на рисунке), и используя простую меру суммирования по столбцу:SumOfAmt =
SUM ( Transactions[Amount] )
CROSSFILTER с третьим аргументом Both:SumOfAmt CF =
CALCULATE (
SUM ( Transactions[Amount] ),
CROSSFILTER ( Accounts[AccountKey], AccountsCustomers[AccountKey], BOTH )
)
Оба способа дают нам ответ на поставленный выше вопрос:
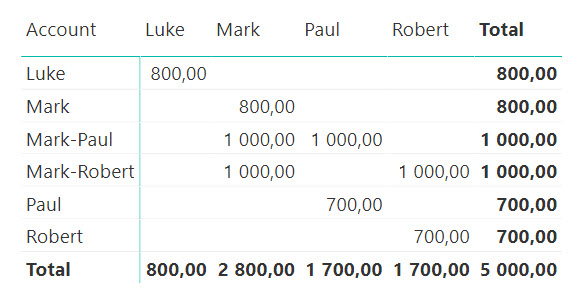
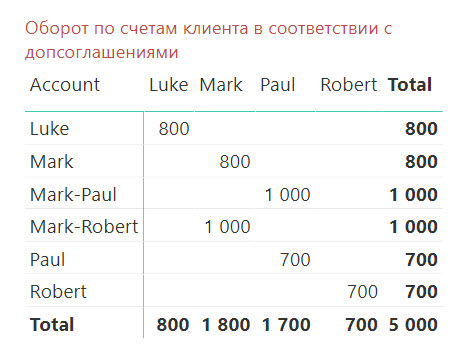
Так, у клиента Mark суммарный оборот по его двум счетам составил 2800 (800 по личному счету «Mark» и по 1000 по совместно управляемым счетам «Mark-Paul» и «Mark-Robert»).
В этой модели нет видимой неоднозначности связей – единственный путь от 'Customers' до 'Transactions' не создает альтернатив.
Чтобы создать ситуацию неоднозначности, я немного модифицировал эту упрощенную модель, добавив еще две таблицы:
'Agreements' – справочник договоров, заключенных с клиентами. У одного клиента может быть несколько договоров.'Addendums' – справочник дополнительных соглашений к договорам. У одного договора может быть несколько дополнительных соглашений.Также я добавил в таблицу 'Transactions' еще один столбец Transactions[AddendumKey], который позволяет определить, в соответствии с каким из дополнительных соглашений была проведена транзакция. Теперь в этой таблице одна строка показывает операцию и в разрезе счёта Transactions[AccountKey], и в разрезе допсоглашения Transactions[AddendumKey].
В итоге модель приобрела вот такой вид:
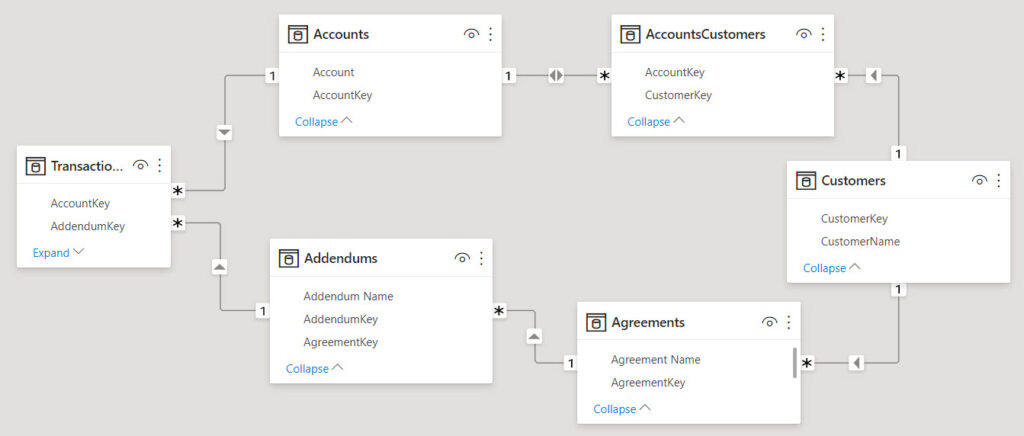
Этот пример не является отражением лучших практик организации модели, я сделал его таким сознательно с единственной целью – продемонстрировать поведение связей.
Теперь между таблицами 'Customers' и 'Transactions' есть два активных пути – через 'Accounts' и через 'Addendums', и связи в модели очевидно неоднозначные. Попробуйте предположить, не заглядывая вперед, по какому же из путей пойдет фильтрация в данном случае?
Если мы теперь посмотрим на результаты расчетов нашей меры [SumOfAmt], то можем увидеть следующую картину:
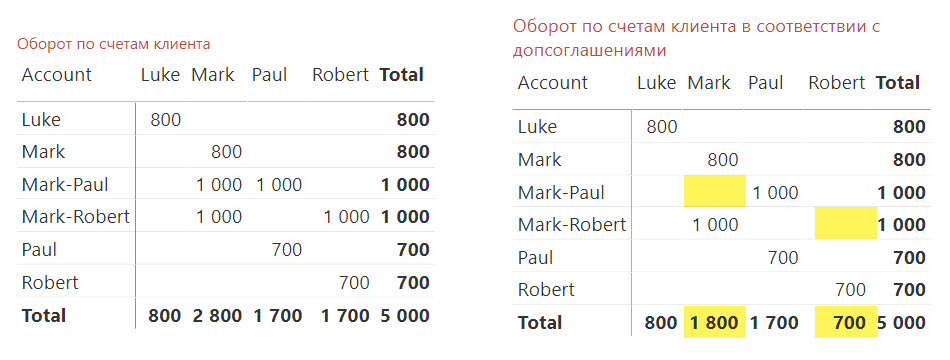
Таблица справа создана в новой модели данных и уже не отвечает на вопрос, поставленный ранее: «Какой оборот по счетам клиента?» Сейчас данные в ней отвечают уже на другой вопрос, который, скорее всего, звучит так: «Какой оборот по счетам клиента с учетом допсоглашений к договорам?»
Очевидно, что в этом случае в действие вступила связь через таблицы 'Agreements' и 'Addendums': несмотря на то, что некоторыми счетами управляют сразу два клиента («Mark-Robert» и «Mark-Paul»), таблица теперь показывает суммы только по допсоглашениям конкретных клиентов. Так, у клиента Mark оборот теперь показывается только по счетам Mark и Mark-Robert, так как операция на 1000 по счету Mark-Paul была проведена по договору клиента Paul. Аналогичная история произошла с оборотами клиента Robert.
Как же понять, почему движком был выбран именно этот путь?
Мы можем увидеть, что эти два активных пути распространения фильтра от 'Customers' имеют одно очень важное отличие: в «верхнем» пути (через 'Accounts') у нас присутствует двунаправленная связь «Многие-к-Одному» между 'AccountsCustomers' и 'Accounts', в то время как в «нижнем» все связи однонаправленные. «Верхний» путь явно проиграл «нижнему» (через 'Addendums') в борьбе за приоритет.
Анализ этой модели и дополнительные изыскания позволили мне сделать вывод о существовании Правила, который подтвердил один из создателей DAX Джеффри Вэнг (Jeffrey Wang):
Путь, в котором фильтрация всегда распространяется только от стороны «Один», будет приоритетнее пути, в котором встречается распространение связи от стороны «Много»
При этом:
В нашей модели фильтр от таблицы 'Customers', проходя по связи между 'AccountsCustomers' и 'Accounts', как раз и сталкивается с такой ситуацией – он должен фильтровать таблицу 'Accounts' в направлении от «Много» к «Один». Анализатор связей в таком случае понижает «вес» такой связи, и движок выбирает тот путь, где такие ситуации не встречаются, т.е. путь через 'Addendums'.
Для того, чтобы наша модель и в этом случае позволила нам получить такой же результат, как и ранее (оборот по счетам клиента без учета допсоглашений), мы должны задействовать отключение одной из связей на «нижнем» пути (например, связи между 'Addendums' и 'Transactions‘) при помощи функции CROSSFILTER и ее 3-го аргумента :
SumSumOfAmt Old Path =
CALCULATE (
[SumOfAmt],
CROSSFILTER ( Transactions[AddendumKey], Addendums[AddendumKey], NONE )
)
Мы знаем, что фунцкия USERELATIONSHIP позволяет нам выбирать, по какой из связей между двумя таблицами должна идти фильтрация. Можем ли мы использовать эту функцию для получения нужного результата в нашей модели?
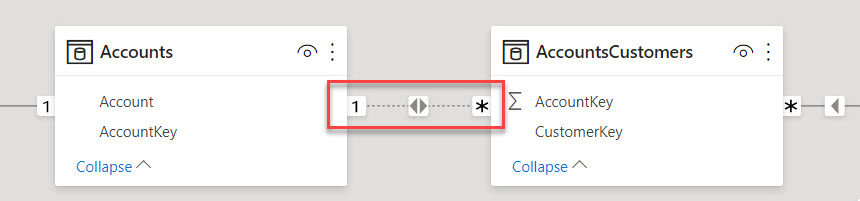
Давайте попробуем сделать неактивной одну из связей на «верхнем» пути (например, между таблицами 'AccountsCustomers' и 'Accounts'), и затем активируем ее при помощи функции USERELATIONSHIP:
SumOfAmtUR =
CALCULATE (
[SumOfAmt],
USERELATIONSHIP ( AccountsCustomers[AccountKey], Accounts[AccountKey] )
)
Как видите, активация связи при помощи USERELATIONSHIP не привела ни к каким изменениям в нашем расчете – фильтрация по-прежнему идет по «нижнему» пути:
В общем-то, трудно было ожидать изменения в данном случае:
'Customers' и 'Transactions' через 'Addendums' сделано не было, второй («нижний») путь по-прежнему приоритетен для движка, в соответствии с выведенным нами Правилом.Таким образом, подводя промежуточный итог, можно сделать следующие выводы:
Казалось бы – всё на этом, мы разобрались? Отнюдь.
Следующий пример я сделал на основе реальной задачи анализа взаимосвязей между документами в Dynamics 365 Finance & Operations (AXAPTA). Как правило, в подобных ей ERP-системах существуют сложные системы отношений, которые не всегда (даже в рамках узконаправленного проекта) можно денормализовать до простой схемы «звезда» или «снежинка».
Пусть в нашей модели есть две таблицы:
'Entries', содержащий в себе ссылки на два разных типа документов: на расходный документ в одном столбце и на приходный документ в другом. Столбец расходных документов Entries[Issue] всегда заполнен уникальными значениями кодов документов, а в столбце приходных документов Entries[Receipt] могут встречаться незаполненные значения.'Documents', содержащий в себе уникальный список документов всех видов и дополнительную информацию, которую нам нужно проанализировать.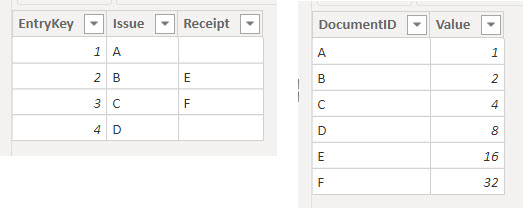
В модели также присутствуют и другие таблицы. Наша задача – построить связи таким образом, чтобы, приходя по связям из других таблиц, фильтрующих таблицу ‘Entries’, получить из таблицы 'Documents' значения, соответствующие либо расходному, либо приходному документу. Иными словами, фильтр должен распространяться от таблицы 'Entries' к таблице 'Documents' в двух вариантах:
Entries[Issue] к Documents[DocumentID]Entries[Receipt] к Documents[DocumentID]Когда мы будем создавать первую связь в Power BI, движок проанализирует кардинальность столбцов с обеих сторон и, убедившись, что все значения в столбцах связи уникальные, автоматически создаст связь «Один-к-Одному»:
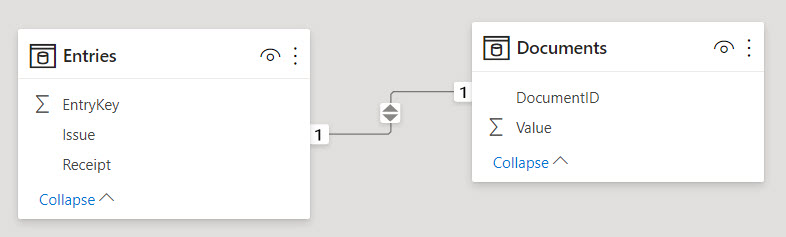
Неизменяемая двунаправленность этой связи нас вполне устраивает – фильтр вполне может проходить от 'Entries' к 'Documents', и наша задача будет отчасти решена.
Вторую связь (от Entries[Receipt] к Documents[DocumentID]) мы не можем сделать такой же «Один-к-Одному», так как наличие пустых значений в столбце Entries[Receipt] уже свидетельствует о неуникальности значений в нем. Поэтому движок автоматически предложит нам неактивную однонаправленную связь «Многие-к-Одному». Направление кросс-фильтрации от 'Documents' к 'Entries' нас не устраивает – нам надо наоборот. Это легко поправимо – в свойствах связи мы можем установить двунаправленную кросс-фильтрацию:
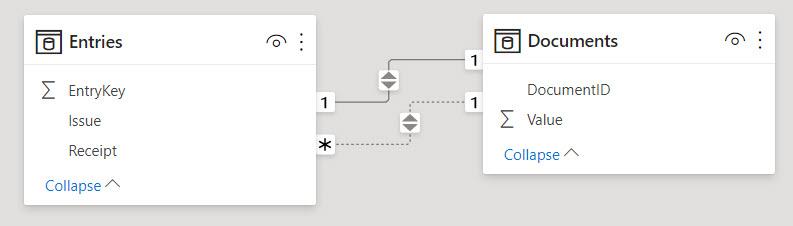
Чтобы получить нужный нам результат, создадим две меры – одна для вычисления суммы по приходным документам, другая – по расходным:
SumOfIssues =
SUM ( Documents[Value] )
SumOfReceipts =
CALCULATE (
SUM ( Documents[Value] ),
USERELATIONSHIP ( Documents[DocumentID], Entries[Receipt] )
)
Мы ожидаем, что первая мера покажет нам суммы по расходным документам (связь по умолчанию), а вторая покажет суммы по приходным (за счет активации второй связи). Однако результат далёк от ожидаемого:
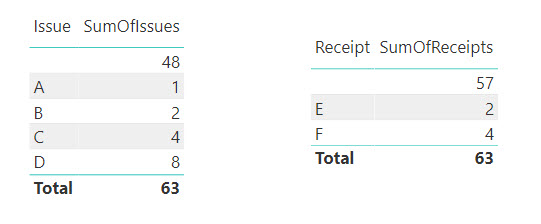
В таблице слева мы получили то, что и должны были – для каждого расходного документа посчитана его сумма, а те документы, которые не нашлись в таблице 'Entries', сгруппировались в пустое значение. Это стандартное поведение.
А вот в правой таблице произошло что-то странное. Если мы еще раз посмотрим на исходные данные, то заметим, что документу E должно соответствовать значение 16, а для F мы должны получить 32. Но мы по-прежнему получили значения для спаренных с E и F расходных документов В и С.
Несмотря на то, что мы активировали связь от столбца Entries[Receipt], движок проигнорировал наш запрос и по-прежнему считает по первой связи – от Entries[Issue]. Это очень странно, неправда ли?
Давайте вспомним, что мы (думаем что) знаем о связях в таком случае:
Эти два пункта на самом деле работают в абсолютном большинстве случаев (а в Power Pivot на настоящий момент – наверное, в 100% случаев). Но здесь что-то пошло не так…
Чтобы не ходить вокруг да около, я просто еще раз приведу здесь то Правило, которое мы вывели ранее в этой статье:
Путь, в котором фильтрация всегда распространяется только от стороны «Один», будет приоритетнее пути, в котором встречается распространение связи от стороны «Много»
Но почему оно сработало здесь? Ведь у нас нет двух активных путей между таблицами, а активация второй связи при помощи USERELATIONSHIP должна была отключить активную связь «Один-к-Одному» по столбцу Entries[Issue] – ведь так всегда происходит?
Я потратил на изучение этой проблемы много часов, анализируя модель, запросы, планы запросов, мучая коллег и знакомых, и, в конце концов, разработчиков Power BI. Делал я это не из праздного любопытства – приведенный пример был частью большой «боевой» модели данных, с которой я работал. В конце концов Джеффри Вэнг дал мне комментарий, который позволил пролить свет на происходящее.
Итак, приготовьтесь:
Сдвиг парадигмы, неправда ли?
Вы можете расценивать такое поведение как баг, как это склонен был оценивать и я – ведь это противоречит нашим представлениям о прямых связях между таблицами. Но, в данном случае, это проблема актуальности наших представлений об окружающем мире.
Система приоритетов связей была введена в целях корректной обработки сложных формул с многими «нанизанными» друг на друга (или вложенными) USERELATIONSHIP, и это очень интересное решение, которое, однако, привело к вот такому столкновению с алгоритмом обработки неоднозначных связей.
Джеффри назвал это поведение «непоследовательностью», и, по зрелому размышлению, я с ним скорее соглашусь: да, не так, как в других случаях, но это то самое «исключение из правил». Очень маловероятно, что это будет изменено, так как может затронуть большое количество работающих моделей. И, опять же, жаль, что это нигде не было описано до сих пор. Но теперь у вас это знание есть 😊
Что же делать в таком случае – как победить правило и получить требуемый результат?
На самом деле – довольно просто, и для этого есть даже не одно решение:
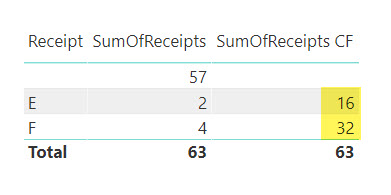
SumOfReceipts CF =
CALCULATE (
SUM ( Documents[Value] ),
USERELATIONSHIP ( Documents[DocumentID], Entries[Receipt] ),
CROSSFILTER ( Documents[DocumentID], Entries[Issue], NONE )
)
Entries[Issue] к Documents[DocumentID] на двунаправленную «Многие-к-Одному». Тогда правило определения приоритета столкнется с двумя однотипными связями и ничего не будет делать, оставив право определения приоритета за USERELATIONSHIP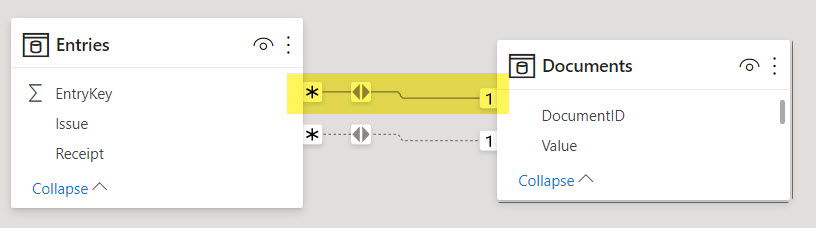
В обоих случаях мы получим нужный результат – фильтрация заработает так, как нам нужно:
Ну и, конечно, мы можем использовать любые варианты виртуальных связей на основе TREATAS, INTERSECT и так далее – с учетом всех связанных с ними нюансов.
В заключение хочу привести еще одну цитату из статьи Альберто Феррари:
The fun part is not in analyzing the numbers; the fun part lies in finding the path that DAX had to discover within the maze to find the exit.
Действительно, DAX нам всегда что-то посчитает (в крайнем случае, выдаст ошибку, если мы грубо ошибемся), но мы должны понимать, что же именно он посчитал. А знание – сила!
Вы можете скачать файл с примерами к данной статье здесь:
Follow me:На днях я провел несколько увлекательных часов, пытаясь найти причину, по которой Power BI отказывался строить связь «один-ко-многим» между двумя таблицами – справочником и таблицей фактов. Эта короткая история в очередной раз говорит нам: «Век живи – век учись»
Ошибка, на которую указывал Power BI, звучит приблизительно так: «невозможно установить связь – как минимум один из столбцов, участвующих в связи, должен содержать уникальные данные»
Связь между двумя столбцами должна была строиться по текстовому полю [SKU Name], содержащему названия SKU (я понимаю, что это не лучший вариант, но таковы условия проекта), источник данных – таблицы Excel.
Так как в таблице фактов значения не предполагали уникальности, было понятно, что нужно искать проблему именно в справочнике, где они должны быть уникальными.
Обнаружить дубликаты в редакторе запросов Power Query не получалось ну совсем никак:
[SKU Name] не изменило количество строк.Text.Clean) значений столбца. Это тоже не помогло удалить дубликаты, но зато увеличилось количество звучащих в моем домашнем офисе непечатных выражений.Table.Distinct(Table, {{“SKU Name”, Comparer.FromCulture(“en-us”, true)}}). Не помогло…Обнаружить дубликаты в источнике (файлах Excel) тоже не получилось – Excel упорно уверял меня, что все значения разные.
В конце концов я сдался и сделал то, что нужно было сделать в самом начале – определить, какой же именно элемент (или элементы) справочника модель данных считает дубликатом.
Я создал простую таблицу, в которую поместил список [SKU Name], и во второй столбец поместил тот же [SKU Name], изменив у него вычисление на подсчет значений.
Бинго! Отсортировав второй столбец по уменьшению, я, наконец, увидел злосчастную SKU:
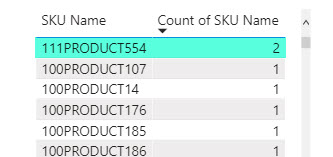
Осталось только понять, почему же эта SKU считается дубликатом в модели, но не обнаруживается как таковой в Power Query и Excel.
Скопировав название SKU, я вернулся в Power Query и отфильтровал многократно очищенный от непечатаемых символов и дубликатов справочник по этому значению.
Угадаете результат? Правильно, я получил одну строку. Никаких дубликатов.

Я на некоторое время завис, не понимая, что делать дальше. «Вы суслика видите? – Нет. – А он есть.»
И тут меня посетила гениальная идея: вместо фильтра столбца по самому значению SKU, я решил проверить, что мне даст фильтр «Текст содержит…»
Вот они, красавицы:

В общем, опустив еще несколько непечатных выражений, резюмирую: эти две строки отличаются лишним пробелом в конце в одной из строк.
Еще немного экспериментов показали:
Вы знаете, вообще-то предупреждать надо… Я перерыл кучу документации и нашел только несколько отсылок к кубам Analysis Services, а также несколько сообщений на форумах, подтверждающих: так задумано, и вряд ли будет изменено в ближайшем времени. Может быть, кто-то сможет найти ссылку на место в документации, где об этом говорится?
Опытные товарищи подсказали, что это поведение соответствует стандарту ANSI SQL. Возможно, это и так, но мне, как пришедшему из мира Excel, это неведомо.
Справиться с этой проблемой можно так:
Text.Trim (или, если вам дороги начальные пробелы, функции Text.TrimEnd) перед удалением дубликатов. Это можно сделать и через интерфейс, кнопками, на вкладке Transform: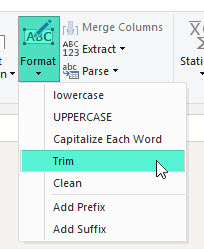
(string)=> if Text.End( string, 1 )=" " then string &"." else stringУдачи, и глядите в оба!
Follow me:
We can connect almost any data source in Power Query, but PowerPivot data model is not included in that extensive list of sources out of the box.
But with the help of the fabulous DAX Studio we can do it (although in my opinion it is still inconvenient and tricky) at least locally – from the same workbook in Excel or from Power BI Desktop.
All you need is to open your Excel workbook, run DAX Studio add-in and connect it to this workbook. Then you can just connect to the PowerPivot model as to SQL Server Analysis Services cube.
But this is an undocumented and extremely limited feature not supported by Microsoft, which can only be used under your own risk.
Continue Reading →Follow me: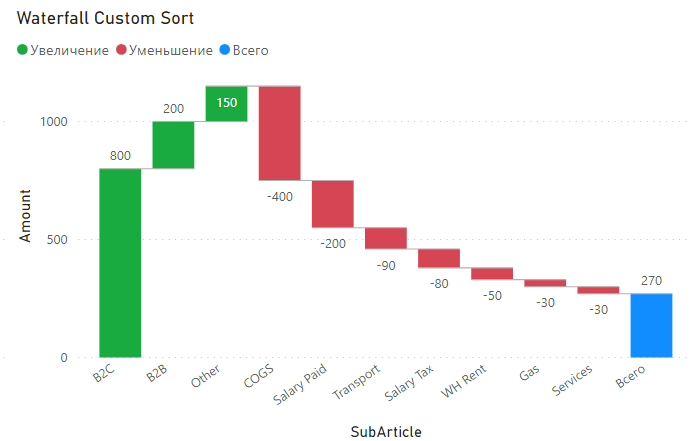
Недавно в чате о Power BI в Telegram был задан вопрос – возможно ли применить для графика Waterfall (каскадная диаграмма, она же «Водопад») нестандартную динамическую сортировку: положительные значения показываются по убыванию, а отрицательные наоборот, по возрастанию (то есть, сначала самые большие по модулю отрицательные значения, затем минуса поменьше и самые мелкие – в конце).
В итоге из такого графика:
Нужно получить вот такой:
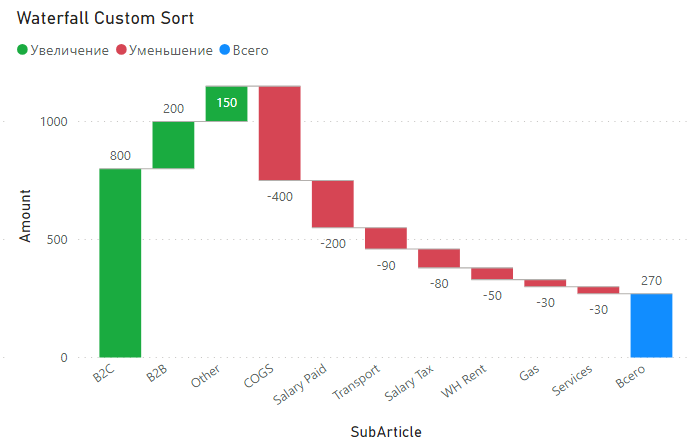
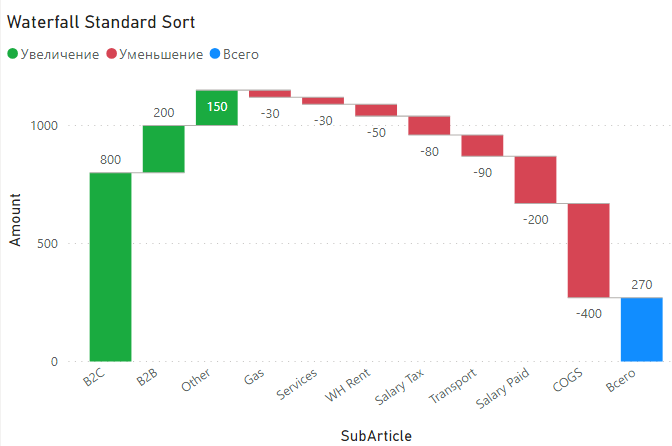
Стандартными средствами мы можем сортировать Waterfall только по возрастанию или убыванию, по обычным правилам (настроить и проверить сортировку можно нажав на три точки в правом верхнем углу визуала):
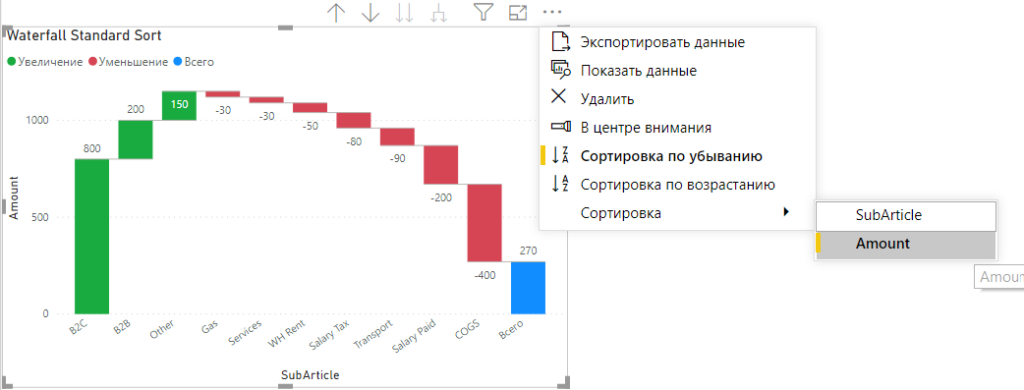
Нам же нужно сделать так, чтобы:
Решение этой задачи делится на две подзадачи:
Первая подзадача в случае визуального элемента Waterfall (каскадная диаграмма) решается просто: мы можем использовать для сортировки любые поля, помещенные в одну из областей визуального элемента.
У Waterfall таких областей четыре:
Первые две используются для определения значений оси X, третья – для определения размера столбиков, а вот четвертая используется для вывода информации во всплывающем окошке при наведении мыши на элемент графика.
Вот ее мы и будем использовать для того, чтобы отсортировать значения на графике в нужном нам порядке.
Скажу сразу – если бы мы не могли использовать эту область для сортировки, то и решение было бы кардинально другим, если бы вообще было.
Вспомним, что сортировка должна учитывать возможность применения пользовательских фильтров, поэтому нам не подойдет вычисляемый столбец в DAX или Power Query). То есть, нам нужна мера.
Теперь нам надо придумать, как создать такую формулу, которая будет давать нам нужный порядок сортировки.
Continue Reading →Follow me:
In this post I describe how to implement the classical incremental refresh scenario for the cloud data sources in Power BI Service for Pro accounts. Step by step. It worth to read.
As I wrote in the previous post, we can implement a semi-incremental refresh for Pro accounts in Power BI, using just dataflows.
The method I described has a main lack: although the “historical” dataflow remains unchanged and will never load data from the source again, the “refreshing” dataflow will load the whole “fresh” part of data repetitively until you change the date intervals manually.
Initially – there’s small amount of data in the “fresh” part…

…but, after some consequential refreshes, it could become significant, and not so fresh.
You can again split “fresh” it in the two parts – “new historical” and “fresh”, and so on. But this is only SEMI-incremental refresh, and, of course, is not a good solution.
It seemed that implement a complete, classic incremental update using just dataflows is impossible.
But, after some investigations, I found a solution which helps to implement the classical incremental refresh scenario, where the fresh data part remains small and fresh, and historical part become updated without querying a data source.
At least for the cloud data sources.
Continue Reading →Follow me:After I published previous blog post about an incremental refresh for Pro accounts in Power BI, Microsoft MVP Parker Stevens from BI Elite channel kindly asked me to record a video for his channel. So here it is.
Here I not only introduce Power BI dataflows and describe the semi-incremental refresh concept, but also show how it works in Power BI Service.
Have a fun!
To my surprise, it has almost 1500 views in two days – not so bad 🙂 I understand that this happened because of hype topic, but, well… now I know how to remove some limitations and perform a CLASSICAL incremental refresh for some types of data sources. Blog post follows.
Follow me: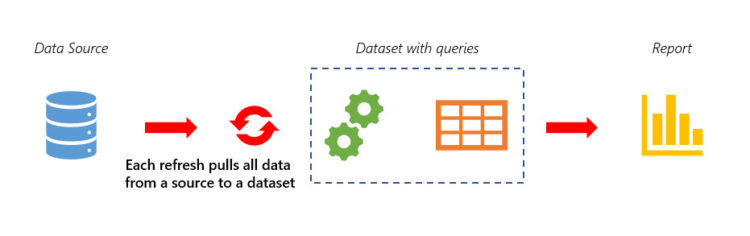
Incremental refresh is a high-demand option in Power BI. Microsoft already provided it for the Premium capacities, but for the Pro accounts it is still in waiting list.
However, with introduction of dataflows in Power BI Service, an incremental refresh implementation becomes available for Pro accounts too.
I won’t to describe dataflows in detail here since there is a lot of blogs and resources about it (but I’ll provide a few links in the bottom of the post).
All you need to know now on how to implement an incremental refresh, is that
Let’s start from this point.
What is the incremental refresh at all? In simple words, it means that in the single data import action we are refreshing (updating) only the part of data instead of loading all the data again and again. In the other words, we are dividing data in two parts (partitions): first part does not need refresh and should remain untouched, second part must be refreshed to bring in updates and corrections.
Continue Reading →Follow me: