Faster Than Joins! Power Query Record as Dictionary: Part 3
Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →Lookup records could be significantly faster than Left Join in Power Query, and there are three different way to create them
Continue Reading →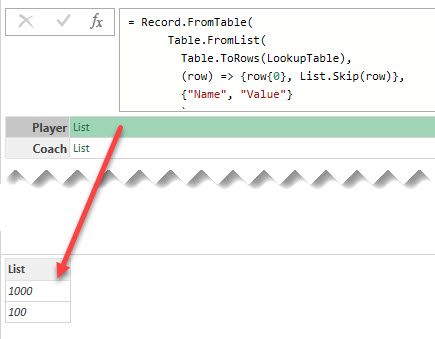
Using the Record.FieldOrDefault function in Power Query to lookup values from dictionary record and handle missing keys
Continue Reading →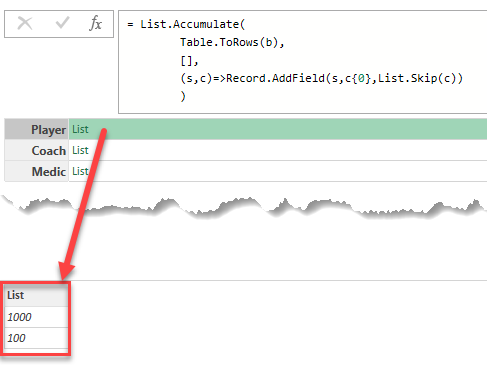
How to use a special dictionary record for a performant lookup for values in Power Query
Continue Reading →
We can connect almost any data source in Power Query, but PowerPivot data model is not included in that extensive list of sources out of the box.
But with the help of the fabulous DAX Studio we can do it (although in my opinion it is still inconvenient and tricky) at least locally – from the same workbook in Excel or from Power BI Desktop.
All you need is to open your Excel workbook, run DAX Studio add-in and connect it to this workbook. Then you can just connect to the PowerPivot model as to SQL Server Analysis Services cube.
But this is an undocumented and extremely limited feature not supported by Microsoft, which can only be used under your own risk.
Continue Reading →Follow me:Recently I needed to do the very simple thing in Power Query. I have the column of numbers and need to check if the values in this column are less than N and then put a corresponding text value in the new column. The function for the new column is something like this:
|
1 |
= if [Values] < 5 then "A" else "B" |
Actually some values are not a numbers but nulls:
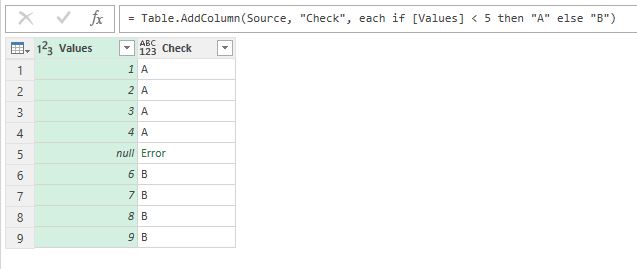
Data contains nulls and comparison return an error
And this simple calculation returns an error for these values!
Why? There is the catch, which is hidden in the depth of documentation (actually on the page 67 of the “Power Query Formula Language Specification (October 2016)” PDF which you can obtain there.
Continue Reading →Follow me: ![]()
![]()
![]()
![]()
List.Generate is the powerful unction of M language (the language of Power Query aka “Get & Transform” for Excel and Power BI query editor), used for lists generation using custom rules. Unlike in other list generators (like List.Repeat or List.Dates), the algorythm (and rules) of creation of successive element could be virtually any. This allows to use List.Generate to implement relatively complex get & transform tasks.
Although there are few excellent posts about this function uses (for example, Chris Webb, Gil Raviv, PowerPivotPro, KenR), I always I always lacked a more “clear” description — «How it actually works?» or «Why don’t it work?» and, at last, «What did the developers kept in mind when create this function?»
As usual, MSDN help article is laconical:
Generates a list of values given four functions that generate the initial value initial , test against a condition condition , and if successful select the result and generate the next value next . An optional parameter, selector , may also be specified.
Will you receive a list of four elements? Do you want to use an optional selector? Really? Why not?
In abandoned Power Query Formula Reference (August 2015) we can find the more clear description:
Generates a list from a value function, a condition function, a next function, and an optional transformation function on the values.
At least it is obvious that this function takes 4 arguments, all of type function:
|
1 |
List.Generate(initial as function, condition as function, next as function, optional selector as nullable function) as list |
Actually List.Generate uses quite simple loop algorythm. When creating an element of a new list, List.Generate evaluates a some variable (lets call it CurrentValue), which then passed from one argument-function to another in a loop:
As you can see from this not-so-technical description, the important difference of List.Generate from other iterator functions of M language is that almost all of others working in “For Each…Next” style (they have a fixed list to loop over), while List.Generate uses other logic – “Do While…Loop”, checking the condition before loop iteration. Subsequently, the number of elements in created list is limited only with “While” condition.
If we’ll write down the algorithm described above in other, non-functional language (like Visual Basic), it will look like that:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Dim NewList As New List CurrentValue = initial() Do While condition(CurrentValue) If selector = null Then NewList.Add(CurrentValue) Else NewList.Add(selector(CurrentValue)) End If CurrentValue = next(CurrentValue) Loop |
Please note:
When you create a list using some API calls (for example, you send GET or POST requests to API in initial and next functions), you should consider the following:
It is convenient when both initial and next return value of type record. This greatly simplifies the addition of counters and passing additional arguments for these functions (for example, one of record fileds is main data, second is counter, etc.).
Resuming, List.Generate is the powerfull tool, looking more complicated than in fact. Hope this post made it more friendly and comprehensible. 🙂
Follow me: ![]()
![]()
![]()
![]()
Recently I posted about UsedRange trap when importing from Excel sheet in Power Query (you can read this post there).
To add an option for users who can meet the same problems as me I’ve added corresponding Power Query improvement ideas on excel.uservoice.com and https://ideas.powerbi.com
Please add your votes to these improvements – I’m sure they can not only save you a few rows of code but also can save you from potential pitfalls when working with raw Excel data.
Thank you!
Follow me: ![]()
![]()
![]()
![]()
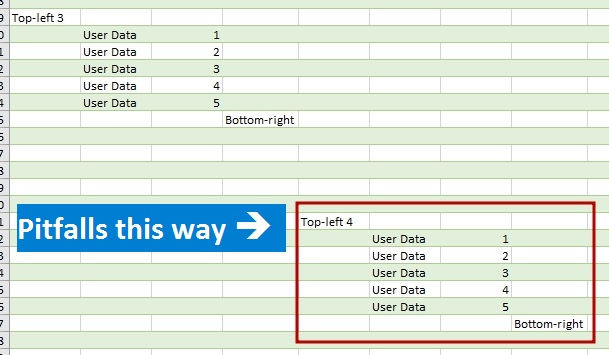
When you import data from an Excel workbook to the Power Query or Power BI from entire sheet, be careful, there is a pitfall.
After linking to an external Excel file there are three options of data extracting available:
In the first case, a Table object is already structured data with columns’ names, automatically transformed to PQ tables. In the second case, Power Query shall give the named range generic titles (Column1, Column2, etc.) and then work as before.
However, it is often the case that data are not structured in a formatted table or named range, and it can be difficult to transform them to such view before import. There can be many reasons for that, e.g., cells format is to be saved (merged cells are no longer merged after transformation) or there are too many files to transform them manually.
Fortunately, Power Query can extract data from the whole sheet. To get data from unformatted sheet you do not need to perform any special actions: just connect to the file, find the needed sheet (it will have “Sheet” value in the [Kind] column) and get data by retrieving its content from the [Data] column:
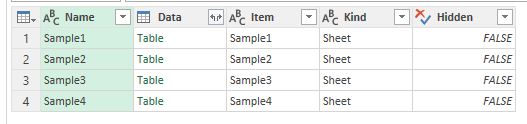
Excel sheets available as data sources just as tables or named ranges
The question is: what data range will be retrieved in that case? There are 17 179 869 184 cells on an Excel sheet (16 384 columns and 1 048 576 rows). If Power Query try to get them all, there will be huge memory consumption and performance leak. However, we can ensure that usually number of imported rows and columns is about the same as the number of rows and columns with the data may be slightly bigger.
So how Power Query defines a data range on a sheet? The answer is out there if you familiar with VBA macros and have enough experience with an Excel object model (but I think you will not be glad with this answer).
Continue Reading →Follow me: ![]()
![]()
![]()
![]()
There are many ways to get a value from parameters table and then pass it to query. One of this methods uses direct selection of unique parameter name. I think it worth a post.
As I described in my first ever post “Absolute and Relative References in Power Query”, when we would like to refer to a single item in a list or a cell in a Power Query table, we can use Name{Argument} syntax: TableName{Row} or ListName{Element} . If Name is a table or list, and Argument is number, then it is simple: we asking for a row or element of such position.
The most commonly used syntax for single cell addressing in tables is
|
1 |
Table{RowNumber}[FieldName] |
But it is often omitted that if Name is a table, Argument could be not a number but a record:
|
1 |
Table{Record} as record |
Value passed as Record in this expression works like a filter for a matching field in the table. For example, [empl_name = “John”] .
How it works and what is in it for practical uses?
If
and
and
then entire record (i.e. row) will be returned as the result of this expression. In other words, a unique matching record from the table.
But there is one important restriction: if there is no unique matching row in the table, an error is raised.
So, when Table{Record} returns a desired result, it has type of record and we can reach a single item from this record by referring to desired field in it:
|
1 |
Table{Record}[Field] |
We can see this method in action when we build query to a table from Excel file. Power Query will create such string of code automatically:
|
1 |
= Excel.CurrentWorkbook(){[Name="Parameters"]}[Content] |
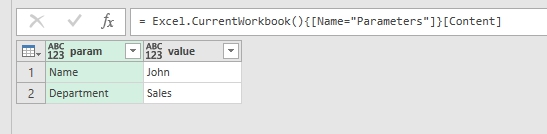
How Power Query refers to a table in Excel workbook
For example, we would like to implement table for passing user-defined parameters to Power Query (I recommend this great post “Building a Parameter Table” by Ken Puls):
|
1 2 3 |
myTable = #table(type table [param = text, value = text],{{"Name","John"},{"Department","Sales"}}), person = myTable{[param = "Name"]}[value], dept = myTable{[param = "Department"]}[value] |
In this example in the first row we create a parameters table with columns param and value that is supposed to be a parameters table for use in other queries.
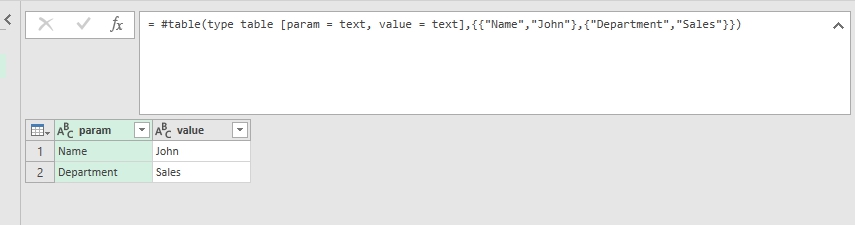
Hardcoded parameters table (just for sample)
Then we got a parameter’s value by applying “record filter” and selecting desired field ( [value]):
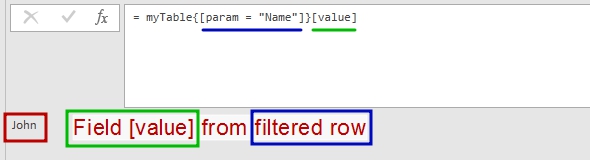
Now we can quickly get “Name” parameter’ value from the table above
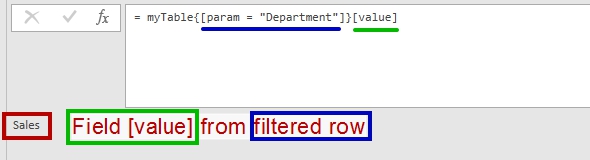
And “Department” parameter’ value from the table above. Any unique parameter.
What are the benefits in this approach?
And, don’t forget that this Table{Record} method has a lot of other uses – when we really need to get a record as a result of expression. Also we can pass a more complex (with 2 or more fields) record as filter.
And Argument record could be a result from other queries. Lets name this query as “QueryRecord”:
|
1 2 3 4 5 |
let Source = #table(type table [Name = text, Department = text, Region=text],{{"John","Sales","AL"},{"Jim","IT","FL"}}), QueriedRecord = Record.RemoveFields(Source{0},{"Region"}) in QueriedRecord |
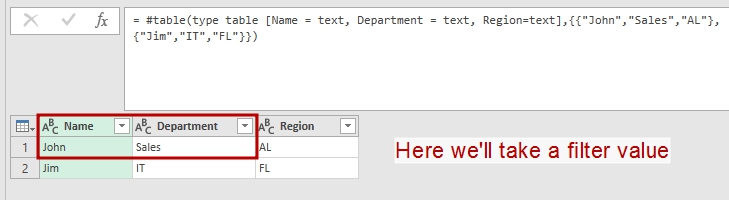
We’ll take a record from this table
The result of above query is a record with two fields: [Name = "John", Department = "Sales"] .
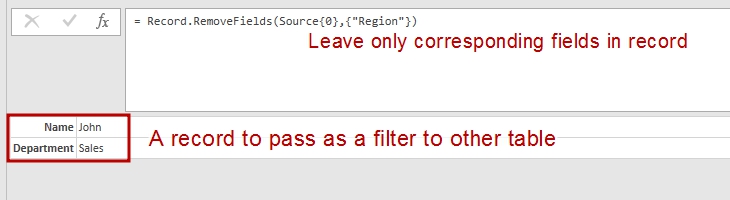
I leaved only needed fileds in this record
Then we pass it as an filter argument to other table:
|
1 2 3 4 5 6 |
let Source = #table(type table [Name = text, Department = text, Date = text],{{"John","Sales","01.01.16"},{"Jim","IT","02.01.16"}}), ChType = Table.TransformColumnTypes(Source,{{"Date", type date}}), Filtered = try ChType{QueryRecord} otherwise null in Filtered |
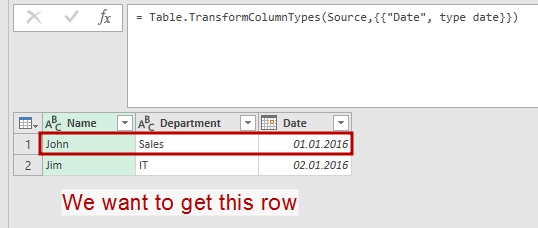
We will filter this table with the result of previous query
The result is a desired record:
|
1 |
[Name = "John", Department = "Sales", Date = "01.01.2016"] |
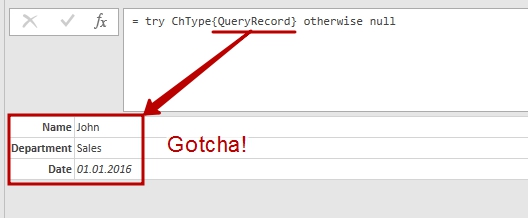
Hey-ho, it works!!!
And a cherry on the cake – quick parameter selection function. You can easy change it for your needs:
|
1 2 3 4 5 |
(param_table as table, param_name as text) => let fnParam = try param_table{[param=param_name]}[value] otherwise null in fnParam |
You can also find a complete description of item selection in “Microsoft Power Query for Excel Formula Language Specification” (see “6.4.1 Item Access” on page 59 in August 2015 edition).
Follow me: ![]()
![]()
![]()
![]()
In my mind List.Accumulate is one of most undocumented and most underestimated functions in Power Query ‘M’ language. In this post I would like to continue explanation of this very interesting iterative function.
In my previous post about List.Accumulate function in Power Query ‘M’ language I’ve mentioned that seed value, passed to function, could be any. As it was described in Gil Raviv post,
The seed argument (or as we call it the initial state), should be of the same type as the first argument of your accumulator function and of the same type as of the function’s output.
Now I want to add more details to an explanation of the List.Accumulate arguments’ behavior:
|
1 2 |
List.Accumulate({1,2,3},0,(state, current)=>(if state = 0 then "" else Text.From(state))&Text.From(current)) // equals “123” |
Let us try to look at how those features could be implemented.
For a starter let’s try to convert the famous Excel function, SUMPRODUCT, to Power Query function.
There are a lot of ways to implement SUMPRODUCT in Power Query. For example, we can add custom column with formula like this: = [Amount] * [Price] and then just get the sum of it. It’s easy and clear, except we need to add this helper column to get just one number.
But let suppose we have got two lists by some query manipulations and these lists are not columns in any table. We can transform them to tables, and then somehow combine those tables, perhaps with Index column, and… looks not as easy as it was with columns in one table?
With List.Accumulate we can do it with just one row of code:
|
1 2 3 4 5 6 |
let myList1 = {1,1,2,2,4,5}, myList2 = {1,4,2,2,1,5}, SUMPRODUCT = List.Accumulate(MyList1, [Sum=0, Index=0], (state, current) => [Sum = current * MyList2{state[Index]}+state[Sum], Index = state[Index]+1])[Sum] in SUMPRODUCT |
Obviously it equals 42.
You can easily transform code from above to the one-row function for future uses:
|
1 2 3 4 5 |
(MyList1 as list, MyList2 as list) as number => let SUMPRODUCT = List.Accumulate(MyList1, [Sum=0, Index=0], (state, current) => [Sum = current * MyList2{state[Index]} + state[Sum], Index = state[Index] + 1])[Sum] in SUMPRODUCT |
Of course, you can enhance it with error handling and other feautures, as you want.
Enjoy! 🙂
(to be continued)Follow me: ![]()
![]()
![]()
![]()